📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
In a nutshell, a machine learning model consumes input data and produces predictions. The quality of the predictions directly corresponds to the quality of data you train the model with; garbage in, garbage out. Check out this article on where it makes sense to use AI and how to properly apply it.
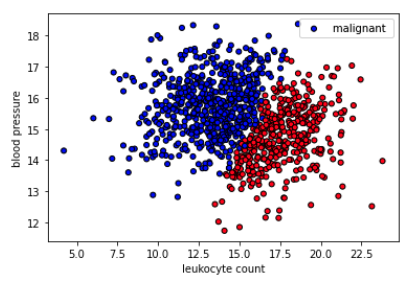
We're going to go through all the concepts with concrete code examples and some synthesized data to train our models on. The task is to determine whether a tumor will be benign (harmless) or malignant (harmful) based on leukocyte (white blood cells) count and blood pressure. This is a synthetic dataset that we created and has no clinical relevance.
Set up
We'll set our seeds for reproducibility.
12
importnumpyasnpimportrandom
1
SEED=1234
123
# Set seed for reproducibilitynp.random.seed(SEED)random.seed(SEED)
Full dataset
We'll first train a model with the entire dataset. Later we'll remove a subset of the dataset and see the effect it has on our model.
We want to choose features that have strong predictive signal for our task. If you want to improve performance, you need to continuously do feature engineering by collecting and adding new signals. So you may run into a new feature that has high correlation (orthogonal signal) with your existing features but it may still possess some unique signal to boost your predictive performance.
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
# Standardize the data (mean=0, std=1) using training dataX_scaler=StandardScaler().fit(X_train)
1234
# Apply scaler on training and test data (don't standardize outputs for classification)X_train=X_scaler.transform(X_train)X_val=X_scaler.transform(X_val)X_test=X_scaler.transform(X_test)
123
# Check (means should be ~0 and std should be ~1)print(f"X_test[0]: mean: {np.mean(X_test[:,0],axis=0):.1f}, std: {np.std(X_test[:,0],axis=0):.1f}")print(f"X_test[1]: mean: {np.mean(X_test[:,1],axis=0):.1f}, std: {np.std(X_test[:,1],axis=0):.1f}")
# Set seed for reproducibilitytorch.manual_seed(SEED)
123
INPUT_DIM=2# X is 2-dimensionalHIDDEN_DIM=100NUM_CLASSES=2
1 2 3 4 5 6 7 8 910
classMLP(nn.Module):def__init__(self,input_dim,hidden_dim,num_classes):super(MLP,self).__init__()self.fc1=nn.Linear(input_dim,hidden_dim)self.fc2=nn.Linear(hidden_dim,num_classes)defforward(self,x_in):z=F.relu(self.fc1(x_in))# ReLU activation function added!z=self.fc2(z)returnz
# Convert data to tensorsX_train=torch.Tensor(X_train)y_train=torch.LongTensor(y_train)X_val=torch.Tensor(X_val)y_val=torch.LongTensor(y_val)X_test=torch.Tensor(X_test)y_test=torch.LongTensor(y_test)
1 2 3 4 5 6 7 8 9101112131415161718192021
# Trainingforepochinrange(NUM_EPOCHS*10):# Forward passy_pred=model(X_train)# Lossloss=loss_fn(y_pred,y_train)# Zero all gradientsoptimizer.zero_grad()# Backward passloss.backward()# Update weightsoptimizer.step()ifepoch%10==0:predictions=y_pred.max(dim=1)[1]# classaccuracy=accuracy_fn(y_pred=predictions,y_true=y_train)print(f"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}")
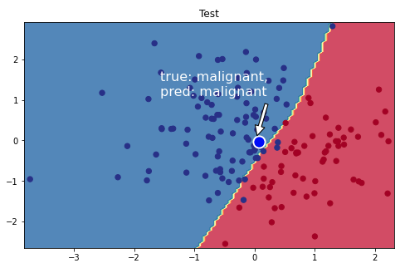
We're going to plot a point, which we know belongs to the malignant tumor class. Our well trained model here would accurately predict that it is indeed a malignant tumor!
# Visualize the decision boundaryplt.figure(figsize=(8,5))plt.title("Test")plot_multiclass_decision_boundary(model=model,X=X_test,y=y_test)# Sample point near the decision boundarymean_leukocyte_count,mean_blood_pressure=X_scaler.transform([[np.mean(df.leukocyte_count),np.mean(df.blood_pressure)]])[0]plt.scatter(mean_leukocyte_count+0.05,mean_blood_pressure-0.05,s=200,c="b",edgecolor="w",linewidth=2)# Annotateplt.annotate("true: malignant,\npred: malignant",color="white",xy=(mean_leukocyte_count,mean_blood_pressure),xytext=(0.4,0.65),textcoords="figure fraction",fontsize=16,arrowprops=dict(facecolor="white",shrink=0.1))plt.show()
Great! We received great performances on both our train and test data splits. We're going to use this dataset to show the importance of data quality.
Reduced dataset
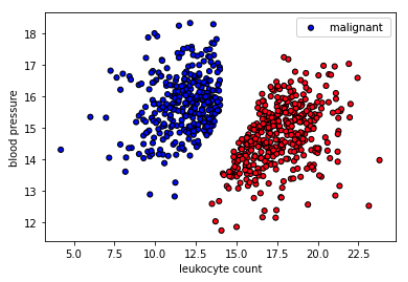
Let's remove some training data near the decision boundary and see how robust the model is now.
Load data
12345
# Raw reduced dataurl="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors_reduced.csv"df_reduced=pd.read_csv(url,header=0)# loaddf_reduced=df_reduced.sample(frac=1).reset_index(drop=True)# shuffledf_reduced.head()
leukocyte_count
blood_pressure
tumor_class
0
16.795186
14.434741
benign
1
13.472969
15.250393
malignant
2
9.840450
16.434717
malignant
3
16.390730
14.419258
benign
4
13.367974
15.741790
malignant
12345
# Define X and yX=df_reduced[["leukocyte_count","blood_pressure"]].valuesy=df_reduced["tumor_class"].valuesprint("X: ",np.shape(X))print("y: ",np.shape(y))
# Encode class labelslabel_encoder=LabelEncoder()label_encoder=label_encoder.fit(y_train)num_classes=len(label_encoder.classes_)y_train=label_encoder.transform(y_train)y_val=label_encoder.transform(y_val)y_test=label_encoder.transform(y_test)
1234
# Class weightscounts=np.bincount(y_train)class_weights={i:1.0/countfori,countinenumerate(counts)}print(f"counts: {counts}\nweights: {class_weights}")
# Standardize inputs using training dataX_scaler=StandardScaler().fit(X_train)X_train=X_scaler.transform(X_train)X_val=X_scaler.transform(X_val)X_test=X_scaler.transform(X_test)
# Convert data to tensorsX_train=torch.Tensor(X_train)y_train=torch.LongTensor(y_train)X_val=torch.Tensor(X_val)y_val=torch.LongTensor(y_val)X_test=torch.Tensor(X_test)y_test=torch.LongTensor(y_test)
1 2 3 4 5 6 7 8 9101112131415161718192021
# Trainingforepochinrange(NUM_EPOCHS*10):# Forward passy_pred=model(X_train)# Lossloss=loss_fn(y_pred,y_train)# Zero all gradientsoptimizer.zero_grad()# Backward passloss.backward()# Update weightsoptimizer.step()ifepoch%10==0:predictions=y_pred.max(dim=1)[1]# classaccuracy=accuracy_fn(y_pred=predictions,y_true=y_train)print(f"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}")
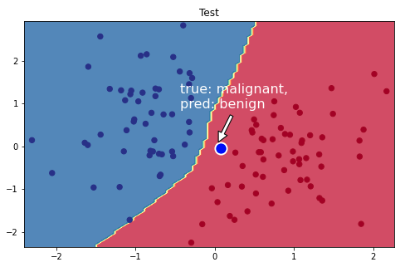
Now let's see how the same inference point from earlier performs now on the model trained on the reduced dataset.
1 2 3 4 5 6 7 8 9101112131415161718
# Visualize the decision boundaryplt.figure(figsize=(8,5))plt.title("Test")plot_multiclass_decision_boundary(model=model,X=X_test,y=y_test)# Sample point near the decision boundary (same point as before)plt.scatter(mean_leukocyte_count+0.05,mean_blood_pressure-0.05,s=200,c="b",edgecolor="w",linewidth=2)# Annotateplt.annotate("true: malignant,\npred: benign",color="white",xy=(mean_leukocyte_count,mean_blood_pressure),xytext=(0.45,0.60),textcoords="figure fraction",fontsize=16,arrowprops=dict(facecolor="white",shrink=0.1))plt.show()
This is a very fragile but highly realistic scenario. Based on our reduced synthetic dataset, we have achieved a model that generalized really well on the test data. But when we ask for the prediction for the same point tested earlier (which we known is malignant), the prediction is now a benign tumor. We would have completely missed the tumor. To mitigate this, we can:
Get more data around the space we are concerned about
Consume predictions with caution when they are close to the decision boundary
Takeaway
Models are not crystal balls. So it's important that before any machine learning, we really look at our data and ask ourselves if it is truly representative for the task we want to solve. The model itself may fit really well and generalize well on your data but if the data is of poor quality to begin with, the model cannot be trusted.
Once you are confident that your data is of good quality, you can finally start thinking about modeling. The type of model you choose depends on many factors, including the task, type of data, complexity required, etc.
So once you figure out what type of model your task needs, start with simple models and then slowly add complexity. You don’t want to start with neural networks right away because that may not be right model for your data and task. Striking this balance in model complexity is one of the key tasks of your data scientists. simple models → complex models
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Data quality - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}