📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
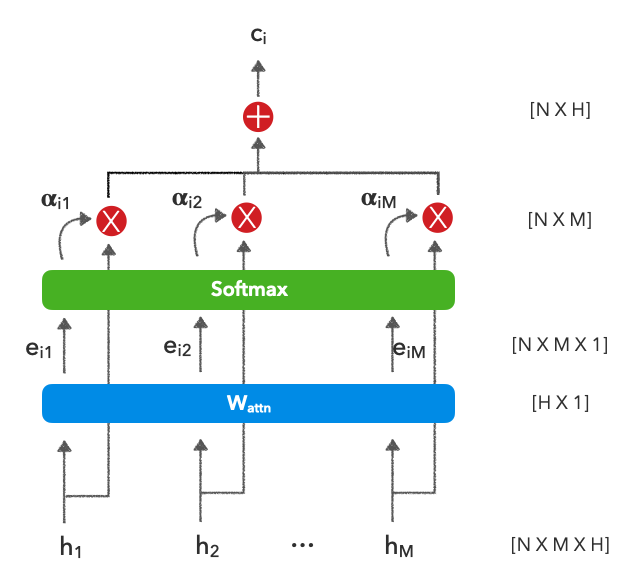
In the RNN lesson, we were constrained to using the representation at the very end but what if we could give contextual weight to each encoded input (\(h_i\)) when making our prediction? This is also preferred because it can help mitigate the vanishing gradient issue which stems from processing very long sequences. Below is attention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
\[ \alpha = softmax(W_{attn}h) \]
\[ c_t = \sum_{i=1}^{n} \alpha_{t,i}h_i \]
Variable
Description
\(N\)
batch size
\(M\)
max sequence length in the batch
\(H\)
hidden dim, model dim, etc.
\(h\)
RNN outputs (or any group of outputs you want to attend to) \(\in \mathbb{R}^{NXMXH}\)
\(\alpha_{t,i}\)
alignment function context vector \(c_t\) (attention in our case) $
\(W_{attn}\)
attention weights to learn \(\in \mathbb{R}^{HX1}\)
\(c_t\)
context vector that accounts for the different inputs with attention
Objective:
At it's core, attention is about learning how to weigh a group of encoded representations to produce a context-aware representation to use for downstream tasks. This is done by learning a set of attention weights and then using softmax to create attention values that sum to 1.
Advantages:
Learn how to account for the appropriate encoded representations regardless of position.
Disadvantages:
Another compute step that involves learning weights.
Miscellaneous:
Several state-of-the-art approaches extend on basic attention to deliver highly context-aware representations (ex. self-attention).
defset_seeds(seed=1234):"""Set seeds for reproducibility."""np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# multi-GPU
12
# Set seeds for reproducibilityset_seeds(seed=SEED)
12345678
# Set devicecuda=Truedevice=torch.device("cuda"if(torch.cuda.is_available()andcuda)else"cpu")torch.set_default_tensor_type("torch.FloatTensor")ifdevice.type=="cuda":torch.set_default_tensor_type("torch.cuda.FloatTensor")print(device)
cuda
Load data
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
Sharon Accepts Plan to Reduce Gaza Army Operation...
World
1
Internet Key Battleground in Wildlife Crime Fight
Sci/Tech
2
July Durable Good Orders Rise 1.7 Percent
Business
3
Growing Signs of a Slowing on Wall Street
Business
4
The New Faces of Reality TV
World
Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
['i', 'me', 'my', 'myself', 'we']
1 2 3 4 5 6 7 8 910111213141516171819
defpreprocess(text,stopwords=STOPWORDS):"""Conditional preprocessing on our text unique to our task."""# Lowertext=text.lower()# Remove stopwordspattern=re.compile(r"\b("+r"|".join(stopwords)+r")\b\s*")text=pattern.sub("",text)# Remove words in parenthesistext=re.sub(r"\([^)]*\)","",text)# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)text=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()returntext
123
# Sampletext="Great week for the NYSE!"preprocess(text=text)
great week nyse
1234
# Apply to dataframepreprocessed_df=df.copy()preprocessed_df.title=preprocessed_df.title.apply(preprocess)print(f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says
sharon accepts plan reduce gaza army operation haaretz says
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
classLabelEncoder(object):"""Label encoder for tag labels."""def__init__(self,class_to_index={}):self.class_to_index=class_to_indexor{}# mutable defaults ;)self.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())def__len__(self):returnlen(self.class_to_index)def__str__(self):returnf"<LabelEncoder(num_classes={len(self)})>"deffit(self,y):classes=np.unique(y)fori,class_inenumerate(classes):self.class_to_index[class_]=iself.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())returnselfdefencode(self,y):encoded=np.zeros((len(y)),dtype=int)fori,iteminenumerate(y):encoded[i]=self.class_to_index[item]returnencodeddefdecode(self,y):classes=[]fori,iteminenumerate(y):classes.append(self.index_to_class[item])returnclassesdefsave(self,fp):withopen(fp,"w")asfp:contents={'class_to_index':self.class_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
classTokenizer(object):def__init__(self,char_level,num_tokens=None,pad_token="<PAD>",oov_token="<UNK>",token_to_index=None):self.char_level=char_levelself.separator=""ifself.char_levelelse" "ifnum_tokens:num_tokens-=2# pad + unk tokensself.num_tokens=num_tokensself.pad_token=pad_tokenself.oov_token=oov_tokenifnottoken_to_index:token_to_index={pad_token:0,oov_token:1}self.token_to_index=token_to_indexself.index_to_token={v:kfork,vinself.token_to_index.items()}def__len__(self):returnlen(self.token_to_index)def__str__(self):returnf"<Tokenizer(num_tokens={len(self)})>"deffit_on_texts(self,texts):ifnotself.char_level:texts=[text.split(" ")fortextintexts]all_tokens=[tokenfortextintextsfortokenintext]counts=Counter(all_tokens).most_common(self.num_tokens)self.min_token_freq=counts[-1][1]fortoken,countincounts:index=len(self)self.token_to_index[token]=indexself.index_to_token[index]=tokenreturnselfdeftexts_to_sequences(self,texts):sequences=[]fortextintexts:ifnotself.char_level:text=text.split(" ")sequence=[]fortokenintext:sequence.append(self.token_to_index.get(token,self.token_to_index[self.oov_token]))sequences.append(np.asarray(sequence))returnsequencesdefsequences_to_texts(self,sequences):texts=[]forsequenceinsequences:text=[]forindexinsequence:text.append(self.index_to_token.get(index,self.oov_token))texts.append(self.separator.join([tokenfortokenintext]))returntextsdefsave(self,fp):withopen(fp,"w")asfp:contents={"char_level":self.char_level,"oov_token":self.oov_token,"token_to_index":self.token_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
Warning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Sample of tokensprint(take(5,tokenizer.token_to_index.items()))print(f"least freq token's freq: {tokenizer.min_token_freq}")# use this to adjust num_tokens
# Convert texts to sequences of indicesX_train=tokenizer.texts_to_sequences(X_train)X_val=tokenizer.texts_to_sequences(X_val)X_test=tokenizer.texts_to_sequences(X_test)preprocessed_text=tokenizer.sequences_to_texts([X_train[0]])[0]print("Text to indices:\n"f" (preprocessed) → {preprocessed_text}\n"f" (tokenized) → {X_train[0]}")
Text to indices:
(preprocessed) → china battles north korea nuclear talks
(tokenized) → [ 16 1491 285 142 114 24]
Padding
We'll need to do 2D padding to our tokenized text.
1234567
defpad_sequences(sequences,max_seq_len=0):"""Pad sequences to max length in sequence."""max_seq_len=max(max_seq_len,max(len(sequence)forsequenceinsequences))padded_sequences=np.zeros((len(sequences),max_seq_len))fori,sequenceinenumerate(sequences):padded_sequences[i][:len(sequence)]=sequencereturnpadded_sequences
classDataset(torch.utils.data.Dataset):def__init__(self,X,y):self.X=Xself.y=ydef__len__(self):returnlen(self.y)def__str__(self):returnf"<Dataset(N={len(self)})>"def__getitem__(self,index):X=self.X[index]y=self.y[index]return[X,len(X),y]defcollate_fn(self,batch):"""Processing on a batch."""# Get inputsbatch=np.array(batch)X=batch[:,0]seq_lens=batch[:,1]y=batch[:,2]# Pad inputsX=pad_sequences(sequences=X)# CastX=torch.LongTensor(X.astype(np.int32))seq_lens=torch.LongTensor(seq_lens.astype(np.int32))y=torch.LongTensor(y.astype(np.int32))returnX,seq_lens,ydefcreate_dataloader(self,batch_size,shuffle=False,drop_last=False):returntorch.utils.data.DataLoader(dataset=self,batch_size=batch_size,collate_fn=self.collate_fn,shuffle=shuffle,drop_last=drop_last,pin_memory=True)
1 2 3 4 5 6 7 8 9101112
# Create datasetstrain_dataset=Dataset(X=X_train,y=y_train)val_dataset=Dataset(X=X_val,y=y_val)test_dataset=Dataset(X=X_test,y=y_test)print("Datasets:\n"f" Train dataset:{train_dataset.__str__()}\n"f" Val dataset: {val_dataset.__str__()}\n"f" Test dataset: {test_dataset.__str__()}\n""Sample point:\n"f" X: {train_dataset[0][0]}\n"f" seq_len: {train_dataset[0][1]}\n"f" y: {train_dataset[0][2]}")
classTrainer(object):def__init__(self,model,device,loss_fn=None,optimizer=None,scheduler=None):# Set paramsself.model=modelself.device=deviceself.loss_fn=loss_fnself.optimizer=optimizerself.scheduler=schedulerdeftrain_step(self,dataloader):"""Train step."""# Set model to train modeself.model.train()loss=0.0# Iterate over train batchesfori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,targets=batch[:-1],batch[-1]self.optimizer.zero_grad()# Reset gradientsz=self.model(inputs)# Forward passJ=self.loss_fn(z,targets)# Define lossJ.backward()# Backward passself.optimizer.step()# Update weights# Cumulative Metricsloss+=(J.detach().item()-loss)/(i+1)returnlossdefeval_step(self,dataloader):"""Validation or test step."""# Set model to eval modeself.model.eval()loss=0.0y_trues,y_probs=[],[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,y_true=batch[:-1],batch[-1]z=self.model(inputs)# Forward passJ=self.loss_fn(z,y_true).item()# Cumulative Metricsloss+=(J-loss)/(i+1)# Store outputsy_prob=torch.sigmoid(z).cpu().numpy()y_probs.extend(y_prob)y_trues.extend(y_true.cpu().numpy())returnloss,np.vstack(y_trues),np.vstack(y_probs)defpredict_step(self,dataloader):"""Prediction step."""# Set model to eval modeself.model.eval()y_probs=[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]y_prob=F.softmax(model(inputs),dim=1)# Store outputsy_probs.extend(y_prob)returnnp.vstack(y_probs)deftrain(self,num_epochs,patience,train_dataloader,val_dataloader):best_val_loss=np.infforepochinrange(num_epochs):# Stepstrain_loss=self.train_step(dataloader=train_dataloader)val_loss,_,_=self.eval_step(dataloader=val_dataloader)self.scheduler.step(val_loss)# Early stoppingifval_loss<best_val_loss:best_val_loss=val_lossbest_model=self.model_patience=patience# reset _patienceelse:_patience-=1ifnot_patience:# 0print("Stopping early!")break# Loggingprint(f"Epoch: {epoch+1} | "f"train_loss: {train_loss:.5f}, "f"val_loss: {val_loss:.5f}, "f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "f"_patience: {_patience}")returnbest_model
Attention
Attention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
\[ \alpha = softmax(W_{attn}h) \]
\[ c_t = \sum_{i=1}^{n} \alpha_{t,i}h_i \]
Variable
Description
\(N\)
batch size
\(M\)
max sequence length in the batch
\(H\)
hidden dim, model dim, etc.
\(h\)
RNN outputs (or any group of outputs you want to attend to) \(\in \mathbb{R}^{NXMXH}\)
\(\alpha_{t,i}\)
alignment function context vector \(c_t\) (attention in our case) $
\(W_{attn}\)
attention weights to learn \(\in \mathbb{R}^{HX1}\)
\(c_t\)
context vector that accounts for the different inputs with attention
1
importtorch.nn.functionalasF
The RNN will create an encoded representation for each word in our input resulting in a stacked vector that has dimensions \(NXMXH\), where N is the # of samples in the batch, M is the max sequence length in the batch, and H is the number of hidden units in the RNN.
# Encodernn=nn.RNN(EMBEDDING_DIM,RNN_HIDDEN_DIM,batch_first=True)out,h_n=rnn(x)# h_n is the last hidden stateprint("out: ",out.shape)print("h_n: ",h_n.shape)
In a many-to-many task such as machine translation, our attentional interface will also account for the encoded representation of token in the output as well (via concatenation) so we can know which encoded inputs to attend to based on the encoded output we're focusing on. For more on this, be sure to explore Bahdanau's attention paper.
Model
Now let's create our RNN based model but with the addition of the attention layer on top of the RNN's outputs.
defget_probability_distribution(y_prob,classes):"""Create a dict of class probabilities from an array."""results={}fori,class_inenumerate(classes):results[class_]=np.float64(y_prob[i])sorted_results={k:vfork,vinsorted(results.items(),key=lambdaitem:item[1],reverse=True)}returnsorted_results
# Dataloadertext="The final tennis tournament starts next week."X=tokenizer.texts_to_sequences([preprocess(text)])print(tokenizer.sequences_to_texts(X))y_filler=label_encoder.encode([label_encoder.classes[0]]*len(X))dataset=Dataset(X=X,y=y_filler)dataloader=dataset.create_dataloader(batch_size=batch_size)
# Get attention valuesattn_vals=interpretable_trainer.predict_step(dataloader)print(attn_vals.shape)# (N, max_seq_len)
1234
# Visualize a bi-gram filter's outputssns.set(rc={"figure.figsize":(10,1)})tokens=tokenizer.sequences_to_texts(X)[0].split(" ")sns.heatmap(attn_vals,xticklabels=tokens)
The word tennis was attended to the most to result in the Sports label.
Types of attention
We'll briefly look at the different types of attention and when to use each them.
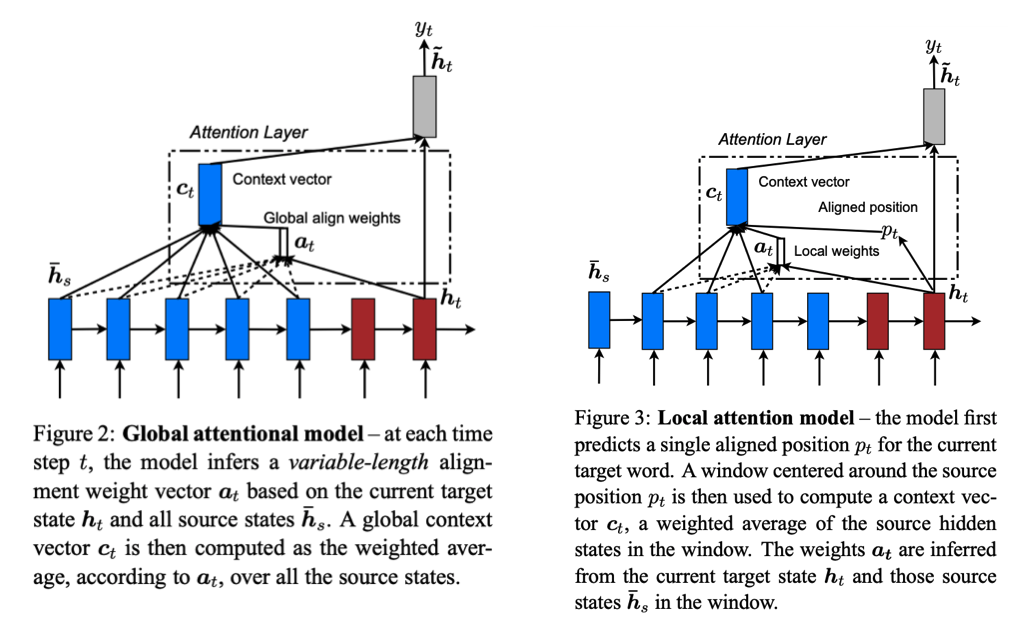
Soft (global) attention
Soft attention the type of attention we've implemented so far, where we attend to all encoded inputs when creating our context vector.
advantages: we always have the ability to attend to all inputs in case something we saw much earlier/ see later are crucial for determining the output.
disadvantages: if our input sequence is very long, this can lead to expensive compute.
Hard attention
Hard attention is focusing on a specific set of the encoded inputs at each time step.
advantages: we can save a lot of compute on long sequences by only focusing on a local patch each time.
disadvantages: non-differentiable and so we need to use more complex techniques (variance reduction, reinforcement learning, etc.) to train.
Local attention blends the advantages of soft and hard attention. It involves learning an aligned position vector and empirically determining a local window of encoded inputs to attend to.
advantages: apply attention to a local patch of inputs yet remain differentiable.
disadvantages: need to determine the alignment vector for each output but it's a worthwhile trade off to determine the right window of inputs to attend to in order to avoid attending to all of them.
We can also use attention within the encoded input sequence to create a weighted representation that based on the similarity between input pairs. This will allow us to create rich representations of the input sequence that are aware of the relationships between each other. For example, in the image below you can see that when composing the representation of the token "its", this specific attention head will be incorporating signal from the token "Law" (it's learned that "its" is referring to the "Law").
In the next lesson, we'll implement Transformers that leverage self-attention to create contextual representations of our inputs for downstream applications.
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Attention - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}