📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
Transformers are a very popular architecture that leverage and extend the concept of self-attention to create very useful representations of our input data for a downstream task.
advantages:
better representation for our input tokens via contextual embeddings where the token representation is based on the specific neighboring tokens using self-attention.
sub-word tokens, as opposed to character tokens, since they can hold more meaningful representation for many of our keywords, prefixes, suffixes, etc.
attend (in parallel) to all the tokens in our input, as opposed to being limited by filter spans (CNNs) or memory issues from sequential processing (RNNs).
disadvantages:
computationally intensive
required large amounts of data (mitigated using pretrained models)
defset_seeds(seed=1234):"""Set seeds for reproducibility."""np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# multi-GPU
12
# Set seeds for reproducibilityset_seeds(seed=SEED)
12345678
# Set devicecuda=Truedevice=torch.device("cuda"if(torch.cuda.is_available()andcuda)else"cpu")torch.set_default_tensor_type("torch.FloatTensor")ifdevice.type=="cuda":torch.set_default_tensor_type("torch.cuda.FloatTensor")print(device)
cuda
Load data
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
Sharon Accepts Plan to Reduce Gaza Army Operation...
World
1
Internet Key Battleground in Wildlife Crime Fight
Sci/Tech
2
July Durable Good Orders Rise 1.7 Percent
Business
3
Growing Signs of a Slowing on Wall Street
Business
4
The New Faces of Reality TV
World
123
# Reduce data size (too large to fit in Colab's limited memory)df=df[:10000]print(len(df))
10000
Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
['i', 'me', 'my', 'myself', 'we']
1 2 3 4 5 6 7 8 910111213141516171819
defpreprocess(text,stopwords=STOPWORDS):"""Conditional preprocessing on our text unique to our task."""# Lowertext=text.lower()# Remove stopwordspattern=re.compile(r"\b("+r"|".join(stopwords)+r")\b\s*")text=pattern.sub("",text)# Remove words in parenthesistext=re.sub(r"\([^)]*\)","",text)# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)text=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()returntext
123
# Sampletext="Great week for the NYSE!"preprocess(text=text)
great week nyse
1234
# Apply to dataframepreprocessed_df=df.copy()preprocessed_df.title=preprocessed_df.title.apply(preprocess)print(f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says
sharon accepts plan reduce gaza army operation haaretz says
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
classLabelEncoder(object):"""Label encoder for tag labels."""def__init__(self,class_to_index={}):self.class_to_index=class_to_indexor{}# mutable defaults ;)self.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())def__len__(self):returnlen(self.class_to_index)def__str__(self):returnf"<LabelEncoder(num_classes={len(self)})>"deffit(self,y):classes=np.unique(y)fori,class_inenumerate(classes):self.class_to_index[class_]=iself.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())returnselfdefencode(self,y):y_one_hot=np.zeros((len(y),len(self.class_to_index)),dtype=int)fori,iteminenumerate(y):y_one_hot[i][self.class_to_index[item]]=1returny_one_hotdefdecode(self,y):classes=[]fori,iteminenumerate(y):index=np.where(item==1)[0][0]classes.append(self.index_to_class[index])returnclassesdefsave(self,fp):withopen(fp,"w")asfp:contents={'class_to_index':self.class_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
# Class weightscounts=np.bincount([label_encoder.class_to_index[class_]forclass_iny_train])class_weights={i:1.0/countfori,countinenumerate(counts)}print(f"counts: {counts}\nweights: {class_weights}")
classTrainer(object):def__init__(self,model,device,loss_fn=None,optimizer=None,scheduler=None):# Set paramsself.model=modelself.device=deviceself.loss_fn=loss_fnself.optimizer=optimizerself.scheduler=schedulerdeftrain_step(self,dataloader):"""Train step."""# Set model to train modeself.model.train()loss=0.0# Iterate over train batchesfori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,targets=batch[:-1],batch[-1]self.optimizer.zero_grad()# Reset gradientsz=self.model(inputs)# Forward passJ=self.loss_fn(z,targets)# Define lossJ.backward()# Backward passself.optimizer.step()# Update weights# Cumulative Metricsloss+=(J.detach().item()-loss)/(i+1)returnlossdefeval_step(self,dataloader):"""Validation or test step."""# Set model to eval modeself.model.eval()loss=0.0y_trues,y_probs=[],[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,y_true=batch[:-1],batch[-1]z=self.model(inputs)# Forward passJ=self.loss_fn(z,y_true).item()# Cumulative Metricsloss+=(J-loss)/(i+1)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)y_trues.extend(y_true.cpu().numpy())returnloss,np.vstack(y_trues),np.vstack(y_probs)defpredict_step(self,dataloader):"""Prediction step."""# Set model to eval modeself.model.eval()y_probs=[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]z=self.model(inputs)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)returnnp.vstack(y_probs)deftrain(self,num_epochs,patience,train_dataloader,val_dataloader):best_val_loss=np.infforepochinrange(num_epochs):# Stepstrain_loss=self.train_step(dataloader=train_dataloader)val_loss,_,_=self.eval_step(dataloader=val_dataloader)self.scheduler.step(val_loss)# Early stoppingifval_loss<best_val_loss:best_val_loss=val_lossbest_model=self.model_patience=patience# reset _patienceelse:_patience-=1ifnot_patience:# 0print("Stopping early!")break# Loggingprint(f"Epoch: {epoch+1} | "f"train_loss: {train_loss:.5f}, "f"val_loss: {val_loss:.5f}, "f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "f"_patience: {_patience}")returnbest_model
Transformer
We'll first learn about the unique components within the Transformer architecture and then implement one for our text classification task.
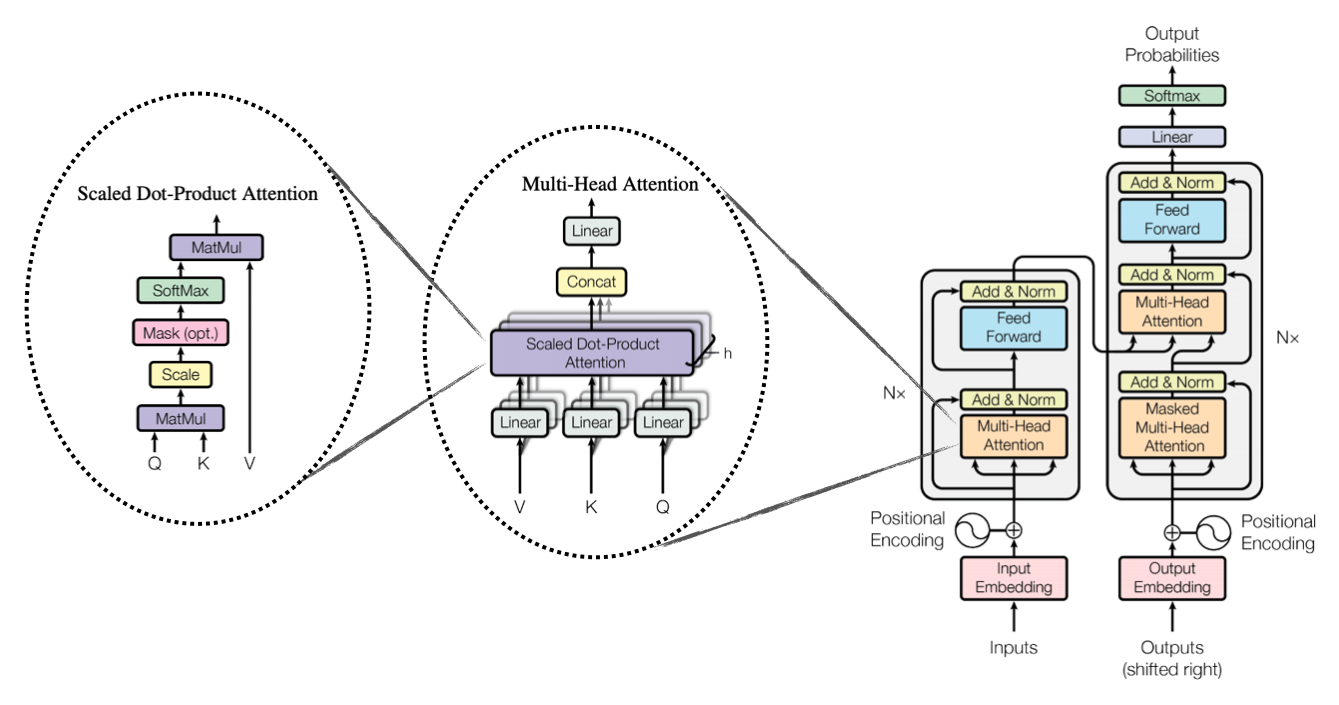
Scaled dot-product attention
The most popular type of self-attention is scaled dot-product attention from the widely-cited Attention is all you need paper. This type of attention involves projecting our encoded input sequences onto three matrices, queries (Q), keys (K) and values (V), whose weights we learn.
Instead of applying self-attention only once across the entire encoded input, we can also separate the input and apply self-attention in parallel (heads) to each input section and concatenate them. This allows the different head to learn unique representations while maintaining the complexity since we split the input into smaller subspaces.
hidden dim (or dimension of the model \(d_{model}\))
Positional encoding
With self-attention, we aren't able to account for the sequential position of our input tokens. To address this, we can use positional encoding to create a representation of the location of each token with respect to the entire sequence. This can either be learned (with weights) or we can use a fixed function that can better extend to create positional encoding for lengths during inference that were not observed during training.
\[ PE_{(pos,2i)} = sin({pos}/{10000^{2i/H}}) \]
\[ PE_{(pos,2i+1)} = cos({pos}/{10000^{2i/H}}) \]
Variable
Description
\(pos\)
position of the token \((1...M)\)
\(i\)
hidden dim \((1..H)\)
This effectively allows us to represent each token's relative position using a fixed function for very large sequences. And because we've constrained the positional encodings to have the same dimensions as our encoded inputs, we can simply concatenate them before feeding them into the multi-head attention heads.
Architecture
And here's how it all fits together! It's an end-to-end architecture that creates these contextual representations and uses an encoder-decoder architecture to predict the outcomes (one-to-one, many-to-one, many-to-many, etc.) Due to the complexity of the architecture, they require massive amounts of data for training without overfitting, however, they can be leveraged as pretrained models to finetune with smaller datasets that are similar to the larger set it was initially trained on.
We're going to use a pretrained BertModel to act as a feature extractor. We'll only use the encoder to receive sequential and pooled outputs (is_decoder=False is default).
We decided to work with the pooled output, but we could have just as easily worked with the sequential output (encoder representation for each sub-token) and applied a CNN (or other decoder options) on top of it.
# Save artifactsfrompathlibimportPathdir=Path("transformers")dir.mkdir(parents=True,exist_ok=True)label_encoder.save(fp=Path(dir,"label_encoder.json"))torch.save(best_model.state_dict(),Path(dir,"model.pt"))withopen(Path(dir,"performance.json"),"w")asfp:json.dump(performance,indent=2,sort_keys=False,fp=fp)
Inference
12345678
defget_probability_distribution(y_prob,classes):"""Create a dict of class probabilities from an array."""results={}fori,class_inenumerate(classes):results[class_]=np.float64(y_prob[i])sorted_results={k:vfork,vinsorted(results.items(),key=lambdaitem:item[1],reverse=True)}returnsorted_results
# Dataloadertext="The final tennis tournament starts next week."X=preprocess(text)encoded_input=tokenizer(X,return_tensors="pt",padding=True).to(torch.device("cpu"))ids=encoded_input["input_ids"]masks=encoded_input["attention_mask"]y_filler=label_encoder.encode([label_encoder.classes[0]]*len(ids))dataset=TransformerTextDataset(ids=ids,masks=masks,targets=y_filler)dataloader=dataset.create_dataloader(batch_size=int(batch_size))
Now we're ready to start the MLOps course to learn how to apply all this foundational modeling knowledge to responsibly develop, deploy and maintain production machine learning applications.
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Transformers - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}