📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
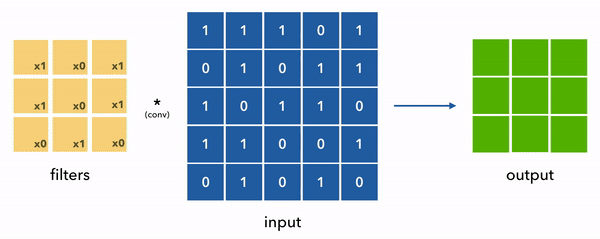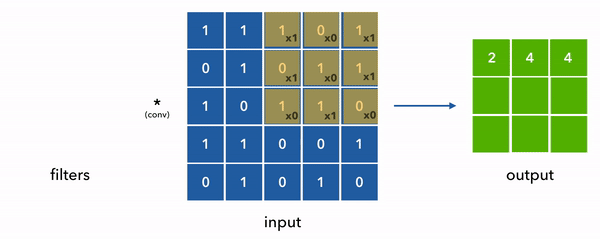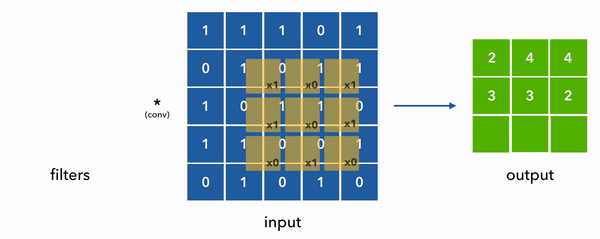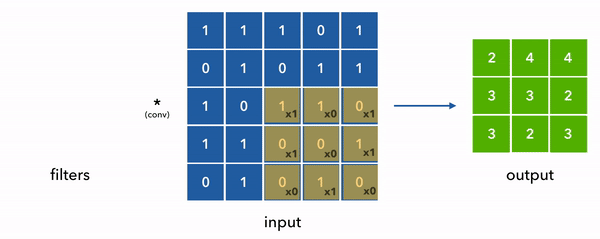
At the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
Objective:
Extract meaningful spatial substructure from encoded data.
defset_seeds(seed=1234):"""Set seeds for reproducibility."""np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# multi-GPU
12
# Set seeds for reproducibilityset_seeds(seed=SEED)
12345678
# Set devicecuda=Truedevice=torch.device("cuda"if(torch.cuda.is_available()andcuda)else"cpu")torch.set_default_tensor_type("torch.FloatTensor")ifdevice.type=="cuda":torch.set_default_tensor_type("torch.cuda.FloatTensor")print(device)
cuda
Load data
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
Sharon Accepts Plan to Reduce Gaza Army Operation...
World
1
Internet Key Battleground in Wildlife Crime Fight
Sci/Tech
2
July Durable Good Orders Rise 1.7 Percent
Business
3
Growing Signs of a Slowing on Wall Street
Business
4
The New Faces of Reality TV
World
Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
['i', 'me', 'my', 'myself', 'we']
1 2 3 4 5 6 7 8 910111213141516171819
defpreprocess(text,stopwords=STOPWORDS):"""Conditional preprocessing on our text unique to our task."""# Lowertext=text.lower()# Remove stopwordspattern=re.compile(r"\b("+r"|".join(stopwords)+r")\b\s*")text=pattern.sub("",text)# Remove words in parenthesistext=re.sub(r"\([^)]*\)","",text)# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)# separate punctuation tied to wordstext=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()returntext
123
# Sampletext="Great week for the NYSE!"preprocess(text=text)
great week nyse
1234
# Apply to dataframepreprocessed_df=df.copy()preprocessed_df.title=preprocessed_df.title.apply(preprocess)print(f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says
sharon accepts plan reduce gaza army operation haaretz says
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
classLabelEncoder(object):"""Label encoder for tag labels."""def__init__(self,class_to_index={}):self.class_to_index=class_to_indexor{}# mutable defaults ;)self.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())def__len__(self):returnlen(self.class_to_index)def__str__(self):returnf"<LabelEncoder(num_classes={len(self)})>"deffit(self,y):classes=np.unique(y)fori,class_inenumerate(classes):self.class_to_index[class_]=iself.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())returnselfdefencode(self,y):encoded=np.zeros((len(y)),dtype=int)fori,iteminenumerate(y):encoded[i]=self.class_to_index[item]returnencodeddefdecode(self,y):classes=[]fori,iteminenumerate(y):classes.append(self.index_to_class[item])returnclassesdefsave(self,fp):withopen(fp,"w")asfp:contents={'class_to_index':self.class_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
Our input data is text and we can't feed it directly to our models. So, we'll define a Tokenizer to convert our text input data into token indices. This means that every token (we can decide what a token is char, word, sub-word, etc.) is mapped to a unique index which allows us to represent our text as an array of indices.
classTokenizer(object):def__init__(self,char_level,num_tokens=None,pad_token="<PAD>",oov_token="<UNK>",token_to_index=None):self.char_level=char_levelself.separator=""ifself.char_levelelse" "ifnum_tokens:num_tokens-=2# pad + unk tokensself.num_tokens=num_tokensself.pad_token=pad_tokenself.oov_token=oov_tokenifnottoken_to_index:token_to_index={pad_token:0,oov_token:1}self.token_to_index=token_to_indexself.index_to_token={v:kfork,vinself.token_to_index.items()}def__len__(self):returnlen(self.token_to_index)def__str__(self):returnf"<Tokenizer(num_tokens={len(self)})>"deffit_on_texts(self,texts):ifnotself.char_level:texts=[text.split(" ")fortextintexts]all_tokens=[tokenfortextintextsfortokenintext]counts=Counter(all_tokens).most_common(self.num_tokens)self.min_token_freq=counts[-1][1]fortoken,countincounts:index=len(self)self.token_to_index[token]=indexself.index_to_token[index]=tokenreturnselfdeftexts_to_sequences(self,texts):sequences=[]fortextintexts:ifnotself.char_level:text=text.split(" ")sequence=[]fortokenintext:sequence.append(self.token_to_index.get(token,self.token_to_index[self.oov_token]))sequences.append(np.asarray(sequence))returnsequencesdefsequences_to_texts(self,sequences):texts=[]forsequenceinsequences:text=[]forindexinsequence:text.append(self.index_to_token.get(index,self.oov_token))texts.append(self.separator.join([tokenfortokenintext]))returntextsdefsave(self,fp):withopen(fp,"w")asfp:contents={"char_level":self.char_level,"oov_token":self.oov_token,"token_to_index":self.token_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
We're going to restrict the number of tokens in our Tokenizer to the top 500 most frequent tokens (stop words already removed) because the full vocabulary size (~35K) is too large to run on Google Colab notebooks.
# Sample of tokensprint(take(5,tokenizer.token_to_index.items()))print(f"least freq token's freq: {tokenizer.min_token_freq}")# use this to adjust num_tokens
# Convert texts to sequences of indicesX_train=tokenizer.texts_to_sequences(X_train)X_val=tokenizer.texts_to_sequences(X_val)X_test=tokenizer.texts_to_sequences(X_test)preprocessed_text=tokenizer.sequences_to_texts([X_train[0]])[0]print("Text to indices:\n"f" (preprocessed) → {preprocessed_text}\n"f" (tokenized) → {X_train[0]}")
Text to indices:
(preprocessed) → china <UNK> north korea nuclear talks
(tokenized) → [ 16 1 285 142 114 24]
Did we need to split the data first?
How come we applied the preprocessing functions to the entire dataset but tokenization after splitting the dataset? Does it matter?
Show answer
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. So for the tokenization process, it's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well. However for global preprocessing steps, like the preprocessing function where we aren't learning anything from the data itself, we can perform before splitting the data.
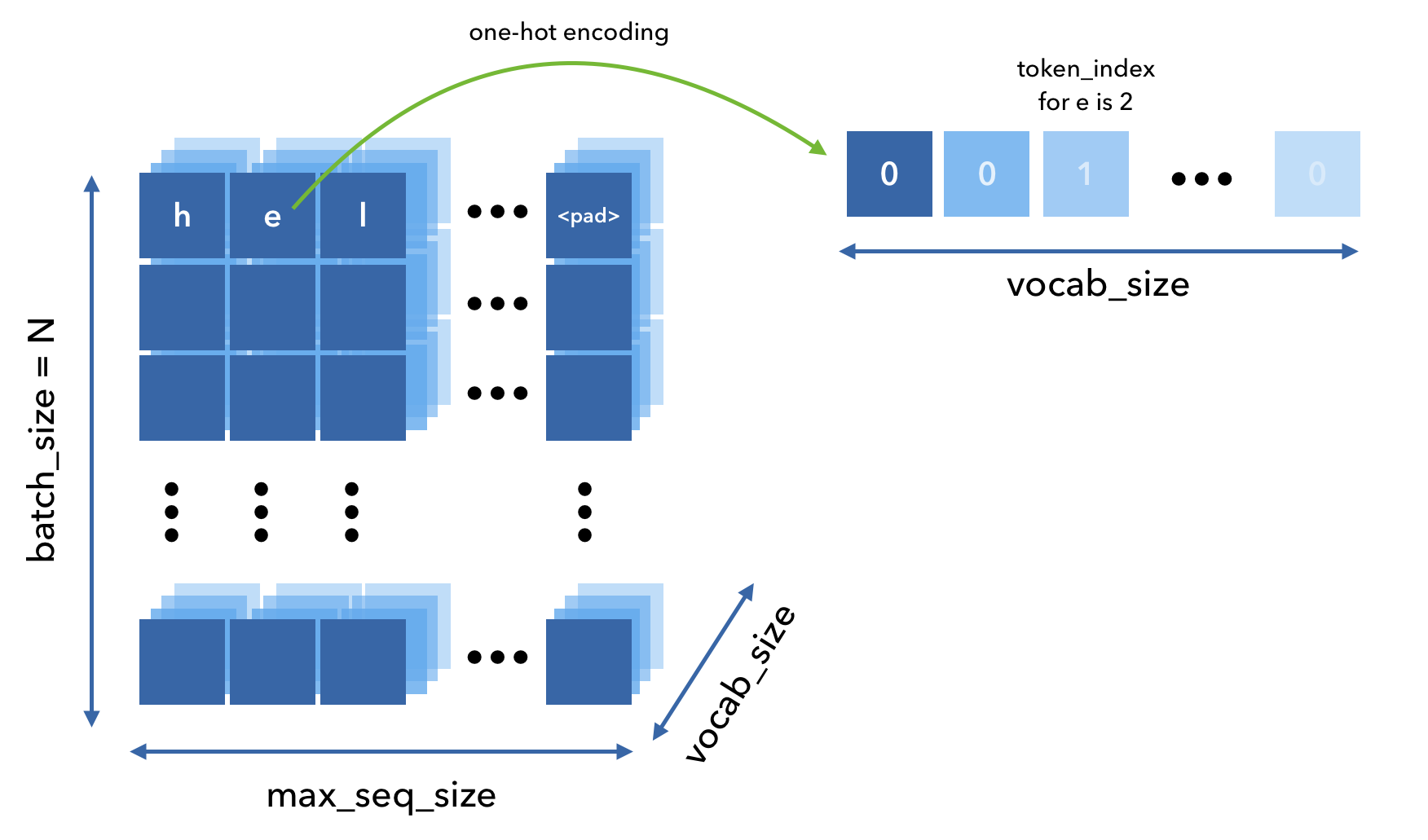
One-hot encoding
One-hot encoding creates a binary column for each unique value for the feature we're trying to map. All of the values in each token's array will be 0 except at the index that this specific token is represented by.
There are 5 words in the vocabulary:
1234567
{"a":0,"e":1,"i":2,"o":3,"u":4}
Then the text aou would be represented by:
123
[[1.0.0.0.0.][0.0.0.1.0.][0.0.0.0.1.]]
One-hot encoding allows us to represent our data in a way that our models can process the data and isn't biased by the actual value of the token (ex. if your labels were actual numbers).
We have already applied one-hot encoding in the previous lessons when we encoded our labels. Each label was represented by a unique index but when determining loss, we effectively use it's one hot representation and compared it to the predicted probability distribution. We never explicitly wrote this out since all of our previous tasks were multi-class which means every input had just one output class, so the 0s didn't affect the loss (though it did matter during back propagation).
123456
defto_categorical(seq,num_classes):"""One-hot encode a sequence of tokens."""one_hot=np.zeros((len(seq),num_classes))fori,iteminenumerate(seq):one_hot[i,item]=1.returnone_hot
# Convert tokens to one-hotvocab_size=len(tokenizer)X_train=[to_categorical(seq,num_classes=vocab_size)forseqinX_train]X_val=[to_categorical(seq,num_classes=vocab_size)forseqinX_val]X_test=[to_categorical(seq,num_classes=vocab_size)forseqinX_test]
Padding
Our inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
One-hot encoding creates a batch of shape (N, max_seq_len, vocab_size) so we'll need to be able to pad 3D sequences.
12345678
defpad_sequences(sequences,max_seq_len=0):"""Pad sequences to max length in sequence."""max_seq_len=max(max_seq_len,max(len(sequence)forsequenceinsequences))num_classes=sequences[0].shape[-1]padded_sequences=np.zeros((len(sequences),max_seq_len,num_classes))fori,sequenceinenumerate(sequences):padded_sequences[i][:len(sequence)]=sequencereturnpadded_sequences
1234
# 3D sequencesprint(X_train[0].shape,X_train[1].shape,X_train[2].shape)padded=pad_sequences(X_train[0:3])print(padded.shape)
(6, 500) (5, 500) (6, 500)
(3, 6, 500)
Is our pad_sequences function properly created?
Notice any assumptions that could lead to hidden bugs?
Show answer
By using np.zeros() to create our padded sequences, we're assuming that our pad token's index is 0. While this is the case for our project, someone could choose to use a different index and this can cause an error. Worst of all, this would be a silent error because all downstream operations would still run normally but our performance will suffer and it may not always be intuitive that this was the cause of issue!
Dataset
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
classDataset(torch.utils.data.Dataset):def__init__(self,X,y,max_filter_size):self.X=Xself.y=yself.max_filter_size=max_filter_sizedef__len__(self):returnlen(self.y)def__str__(self):returnf"<Dataset(N={len(self)})>"def__getitem__(self,index):X=self.X[index]y=self.y[index]return[X,y]defcollate_fn(self,batch):"""Processing on a batch."""# Get inputsbatch=np.array(batch)X=batch[:,0]y=batch[:,1]# Pad sequencesX=pad_sequences(X,max_seq_len=self.max_filter_size)# CastX=torch.FloatTensor(X.astype(np.int32))y=torch.LongTensor(y.astype(np.int32))returnX,ydefcreate_dataloader(self,batch_size,shuffle=False,drop_last=False):returntorch.utils.data.DataLoader(dataset=self,batch_size=batch_size,collate_fn=self.collate_fn,shuffle=shuffle,drop_last=drop_last,pin_memory=True)
1 2 3 4 5 6 7 8 91011
# Create datasets for embeddingtrain_dataset=Dataset(X=X_train,y=y_train,max_filter_size=FILTER_SIZE)val_dataset=Dataset(X=X_val,y=y_val,max_filter_size=FILTER_SIZE)test_dataset=Dataset(X=X_test,y=y_test,max_filter_size=FILTER_SIZE)print("Datasets:\n"f" Train dataset:{train_dataset.__str__()}\n"f" Val dataset: {val_dataset.__str__()}\n"f" Test dataset: {test_dataset.__str__()}\n""Sample point:\n"f" X: {test_dataset[0][0]}\n"f" y: {test_dataset[0][1]}")
We're going to learn about CNNs by applying them on 1D text data.
Inputs
In the dummy example below, our inputs are composed of character tokens that are one-hot encoded. We have a batch of N samples, where each sample has 8 characters and each character is represented by an array of 10 values (vocab size=10). This gives our inputs the size (N, 8, 10).
With PyTorch, when dealing with convolution, our inputs (X) need to have the channels as the second dimension, so our inputs will be (N, 10, 8).
# Assume all our inputs are padded to have the same # of wordsbatch_size=64max_seq_len=8# words per inputvocab_size=10# one hot sizex=torch.randn(batch_size,max_seq_len,vocab_size)print(f"X: {x.shape}")x=x.transpose(1,2)print(f"X: {x.shape}")
This diagram above is for char-level tokens but extends to any level of tokenization.
Filters
At the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
We can see convolution in the diagram below where we simplified the filters and inputs to be 2D for ease of visualization. Also note that the values are 0/1s but in reality they can be any floating point value.
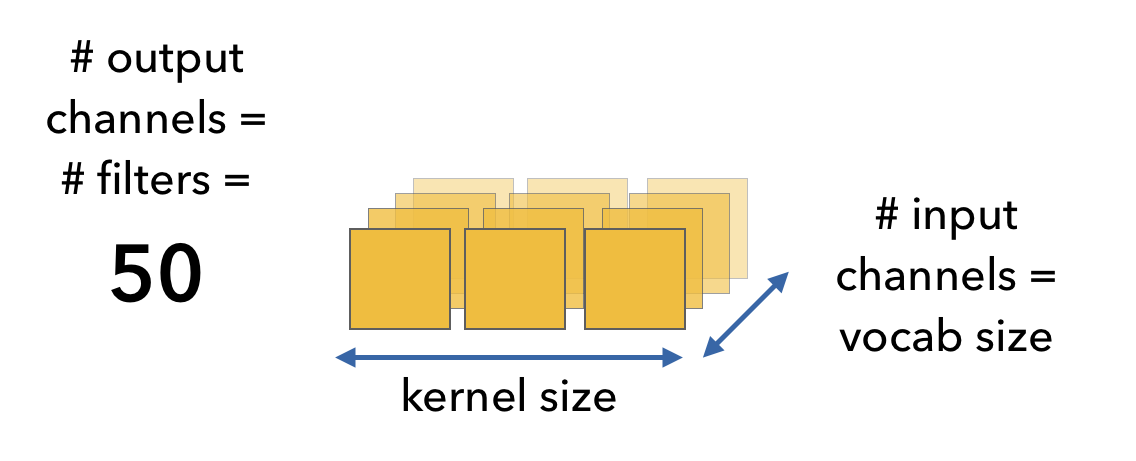
Now let's return to our actual inputs x, which is of shape (8, 10) [max_seq_len, vocab_size] and we want to convolve on this input using filters. We will use 50 filters that are of size (1, 3) and has the same depth as the number of channels (num_channels = vocab_size = one_hot_size = 10). This gives our filter a shape of (3, 10, 50) [kernel_size, vocab_size, num_filters]
stride: amount the filters move from one convolution operation to the next.
padding: values (typically zero) padded to the input, typically to create a volume with whole number dimensions.
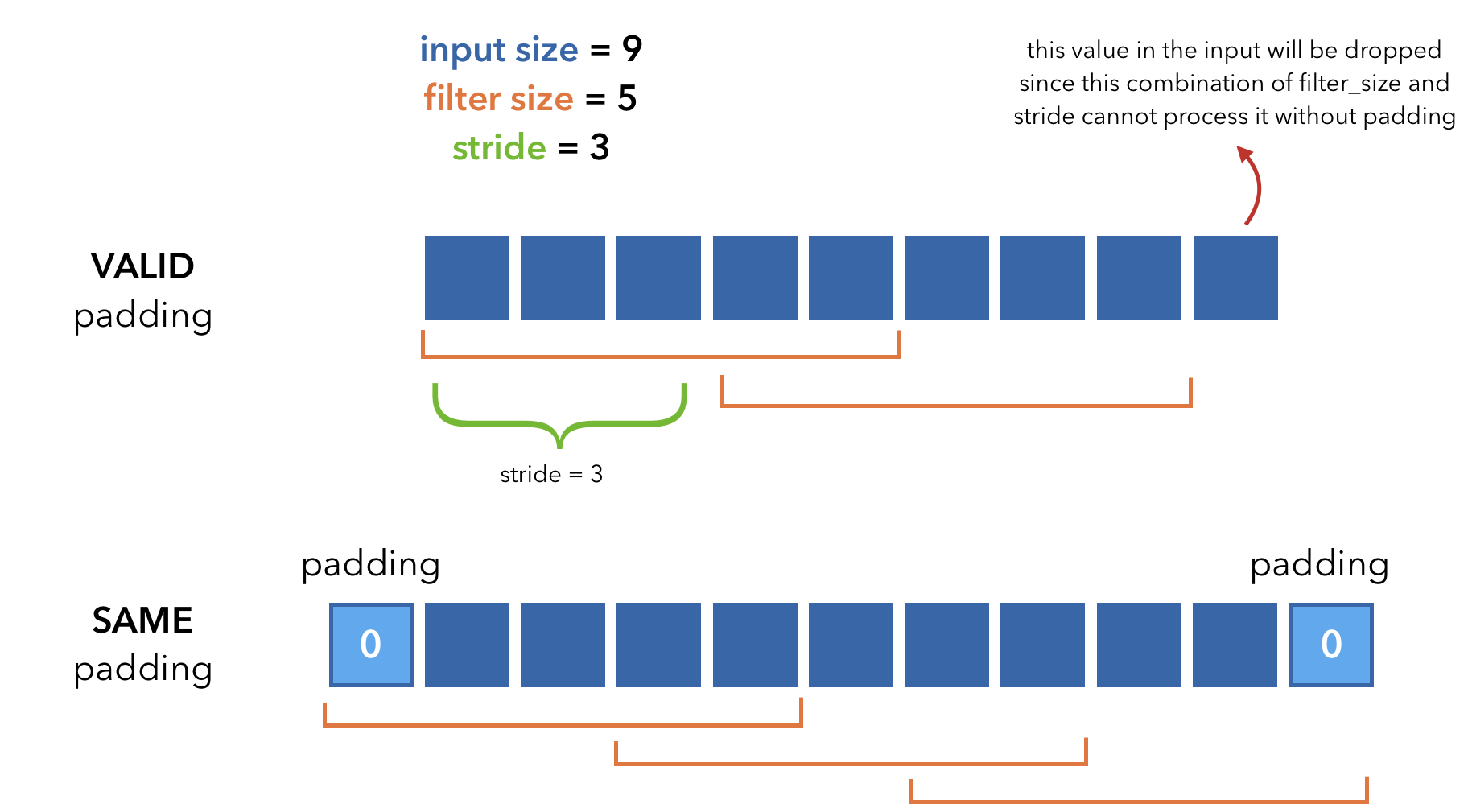
So far we've used a stride of 1 and VALID padding (no padding) but let's look at an example with a higher stride and difference between different padding approaches.
Padding types:
VALID: no padding, the filters only use the "valid" values in the input. If the filter cannot reach all the input values (filters go left to right), the extra values on the right are dropped.
SAME: adds padding evenly to the right (preferred) and left sides of the input so that all values in the input are processed.
We're going to use the Conv1d layer to process our inputs.
1 2 3 4 5 6 7 8 910
# Convolutional filters (VALID padding)vocab_size=10# one hot sizenum_filters=50# num filtersfilter_size=3# filters are 3X3stride=1padding=0# valid padding (no padding)conv1=nn.Conv1d(in_channels=vocab_size,out_channels=num_filters,kernel_size=filter_size,stride=stride,padding=padding,padding_mode="zeros")print("conv: {}".format(conv1.weight.shape))
conv: torch.Size([50, 10, 3])
123
# Forward passz=conv1(x)print(f"z: {z.shape}")
z: torch.Size([64, 50, 6])
When we apply these filter on our inputs, we receive an output of shape (N, 6, 50). We get 50 for the output channel dim because we used 50 filters and 6 for the conv outputs because:
Now we'll add padding so that the convolutional outputs are the same shape as our inputs. The amount of padding for the SAME padding can be determined using the same equation. We want out output to have the same width as our input, so we solve for P:
\[ \frac{W-F+2P}{S} + 1 = W \]
\[ P = \frac{S(W-1) - W + F}{2} \]
If \(P\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
12345678
# Convolutional filters (SAME padding)vocab_size=10# one hot sizenum_filters=50# num filtersfilter_size=3# filters are 3X3stride=1conv=nn.Conv1d(in_channels=vocab_size,out_channels=num_filters,kernel_size=filter_size,stride=stride)print("conv: {}".format(conv.weight.shape))
We will explore larger dimensional convolution layers in subsequent lessons. For example, Conv2D is used with 3D inputs (images, char-level text, etc.) and Conv3D is used for 4D inputs (videos, time-series, etc.).
Pooling
The result of convolving filters on an input is a feature map. Due to the nature of convolution and overlaps, our feature map will have lots of redundant information. Pooling is a way to summarize a high-dimensional feature map into a lower dimensional one for simplified downstream computation. The pooling operation can be the max value, average, etc. in a certain receptive field. Below is an example of pooling where the outputs from a conv layer are 4X4 and we're going to apply max pool filters of size 2X2.
In our use case, we want to just take the one max value so we will use the MaxPool1D layer, so our max-pool filter size will be max_seq_len.
123
# Max poolingpool_output=F.max_pool1d(z,z.size(2))print("Size: {}".format(pool_output.shape))
Size: torch.Size([64, 50, 1])
Batch normalization
The last topic we'll cover before constructing our model is batch normalization. It's an operation that will standardize (mean=0, std=1) the activations from the previous layer. Recall that we used to standardize our inputs in previous notebooks so our model can optimize quickly with larger learning rates. It's the same concept here but we continue to maintain standardized values throughout the repeated forward passes to further aid optimization.
1234
# Batch normalizationbatch_norm=nn.BatchNorm1d(num_features=num_filters)z=batch_norm(conv(x))# applied to activations (after conv layer & before pooling)print(f"z: {z.shape}")
z: torch.Size([64, 50, 6])
12
# Mean and std before batchnormprint(f"mean: {torch.mean(conv(x)):.2f}, std: {torch.std(conv(x)):.2f}")
mean: -0.00, std: 0.57
12
# Mean and std after batchnormprint(f"mean: {torch.mean(z):.2f}, std: {torch.std(z):.2f}")
mean: 0.00, std: 1.00
Modeling
Model
Let's visualize the model's forward pass.
We'll first tokenize our inputs (batch_size, max_seq_len).
Then we'll one-hot encode our tokenized inputs (batch_size, max_seq_len, vocab_size).
We'll apply convolution via filters (filter_size, vocab_size, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors.
We'll apply 1D global max pooling which will extract the most relevant information from the feature maps for making the decision.
We feed the pool outputs to a fully-connected (FC) layer (with dropout).
We use one more FC layer with softmax to derive class probabilities.
classCNN(nn.Module):def__init__(self,vocab_size,num_filters,filter_size,hidden_dim,dropout_p,num_classes):super(CNN,self).__init__()# Convolutional filtersself.filter_size=filter_sizeself.conv=nn.Conv1d(in_channels=vocab_size,out_channels=num_filters,kernel_size=filter_size,stride=1,padding=0,padding_mode="zeros")self.batch_norm=nn.BatchNorm1d(num_features=num_filters)# FC layersself.fc1=nn.Linear(num_filters,hidden_dim)self.dropout=nn.Dropout(dropout_p)self.fc2=nn.Linear(hidden_dim,num_classes)defforward(self,inputs,channel_first=False,):# Rearrange input so num_channels is in dim 1 (N, C, L)x_in,=inputsifnotchannel_first:x_in=x_in.transpose(1,2)# Padding for `SAME` paddingmax_seq_len=x_in.shape[2]padding_left=int((self.conv.stride[0]*(max_seq_len-1)-max_seq_len+self.filter_size)/2)padding_right=int(math.ceil((self.conv.stride[0]*(max_seq_len-1)-max_seq_len+self.filter_size)/2))# Conv outputsz=self.conv(F.pad(x_in,(padding_left,padding_right)))z=F.max_pool1d(z,z.size(2)).squeeze(2)# FC layerz=self.fc1(z)z=self.dropout(z)z=self.fc2(z)returnz
12345
# Initialize modelmodel=CNN(vocab_size=VOCAB_SIZE,num_filters=NUM_FILTERS,filter_size=FILTER_SIZE,hidden_dim=HIDDEN_DIM,dropout_p=DROPOUT_P,num_classes=NUM_CLASSES)model=model.to(device)# set deviceprint(model.named_parameters)
We used SAME padding (w/ stride=1) which means that the conv outputs will have the same width (max_seq_len) as our inputs. The amount of padding differs for each batch based on the max_seq_len but you can calculate it by solving for P in the equation below.
\[ P = \frac{\text{stride}(\text{max_seq_len}-1) - \text{max_seq_len} + \text{filter_size}}{2} \]
If \(P\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
Training
Let's create the Trainer class that we'll use to facilitate training for our experiments. Notice that we're now moving the train function inside this class.
classTrainer(object):def__init__(self,model,device,loss_fn=None,optimizer=None,scheduler=None):# Set paramsself.model=modelself.device=deviceself.loss_fn=loss_fnself.optimizer=optimizerself.scheduler=schedulerdeftrain_step(self,dataloader):"""Train step."""# Set model to train modeself.model.train()loss=0.0# Iterate over train batchesfori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,targets=batch[:-1],batch[-1]self.optimizer.zero_grad()# Reset gradientsz=self.model(inputs)# Forward passJ=self.loss_fn(z,targets)# Define lossJ.backward()# Backward passself.optimizer.step()# Update weights# Cumulative Metricsloss+=(J.detach().item()-loss)/(i+1)returnlossdefeval_step(self,dataloader):"""Validation or test step."""# Set model to eval modeself.model.eval()loss=0.0y_trues,y_probs=[],[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,y_true=batch[:-1],batch[-1]z=self.model(inputs)# Forward passJ=self.loss_fn(z,y_true).item()# Cumulative Metricsloss+=(J-loss)/(i+1)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)y_trues.extend(y_true.cpu().numpy())returnloss,np.vstack(y_trues),np.vstack(y_probs)defpredict_step(self,dataloader):"""Prediction step."""# Set model to eval modeself.model.eval()y_probs=[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]z=self.model(inputs)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)returnnp.vstack(y_probs)deftrain(self,num_epochs,patience,train_dataloader,val_dataloader):best_val_loss=np.infforepochinrange(num_epochs):# Stepstrain_loss=self.train_step(dataloader=train_dataloader)val_loss,_,_=self.eval_step(dataloader=val_dataloader)self.scheduler.step(val_loss)# Early stoppingifval_loss<best_val_loss:best_val_loss=val_lossbest_model=self.model_patience=patience# reset _patienceelse:_patience-=1ifnot_patience:# 0print("Stopping early!")break# Loggingprint(f"Epoch: {epoch+1} | "f"train_loss: {train_loss:.5f}, "f"val_loss: {val_loss:.5f}, "f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "f"_patience: {_patience}")returnbest_model
# Save artifactsdir=Path("cnn")dir.mkdir(parents=True,exist_ok=True)label_encoder.save(fp=Path(dir,"label_encoder.json"))tokenizer.save(fp=Path(dir,'tokenizer.json'))torch.save(best_model.state_dict(),Path(dir,"model.pt"))withopen(Path(dir,'performance.json'),"w")asfp:json.dump(performance,indent=2,sort_keys=False,fp=fp)
Inference
12345678
defget_probability_distribution(y_prob,classes):"""Create a dict of class probabilities from an array."""results={}fori,class_inenumerate(classes):results[class_]=np.float64(y_prob[i])sorted_results={k:vfork,vinsorted(results.items(),key=lambdaitem:item[1],reverse=True)}returnsorted_results
# Dataloadertext="What a day for the new york stock market to go bust!"sequences=tokenizer.texts_to_sequences([preprocess(text)])print(tokenizer.sequences_to_texts(sequences))X=[to_categorical(seq,num_classes=len(tokenizer))forseqinsequences]y_filler=label_encoder.encode([label_encoder.classes[0]]*len(X))dataset=Dataset(X=X,y=y_filler,max_filter_size=FILTER_SIZE)dataloader=dataset.create_dataloader(batch_size=batch_size)
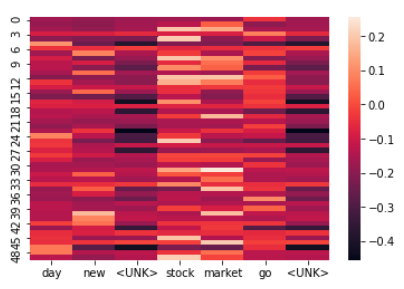
We went through all the trouble of padding our inputs before convolution to result in outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
classInterpretableCNN(nn.Module):def__init__(self,vocab_size,num_filters,filter_size,hidden_dim,dropout_p,num_classes):super(InterpretableCNN,self).__init__()# Convolutional filtersself.filter_size=filter_sizeself.conv=nn.Conv1d(in_channels=vocab_size,out_channels=num_filters,kernel_size=filter_size,stride=1,padding=0,padding_mode="zeros")self.batch_norm=nn.BatchNorm1d(num_features=num_filters)# FC layersself.fc1=nn.Linear(num_filters,hidden_dim)self.dropout=nn.Dropout(dropout_p)self.fc2=nn.Linear(hidden_dim,num_classes)defforward(self,inputs,channel_first=False):# Rearrange input so num_channels is in dim 1 (N, C, L)x_in,=inputsifnotchannel_first:x_in=x_in.transpose(1,2)# Padding for `SAME` paddingmax_seq_len=x_in.shape[2]padding_left=int((self.conv.stride[0]*(max_seq_len-1)-max_seq_len+self.filter_size)/2)padding_right=int(math.ceil((self.conv.stride[0]*(max_seq_len-1)-max_seq_len+self.filter_size)/2))# Conv outputsz=self.conv(F.pad(x_in,(padding_left,padding_right)))returnz