📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
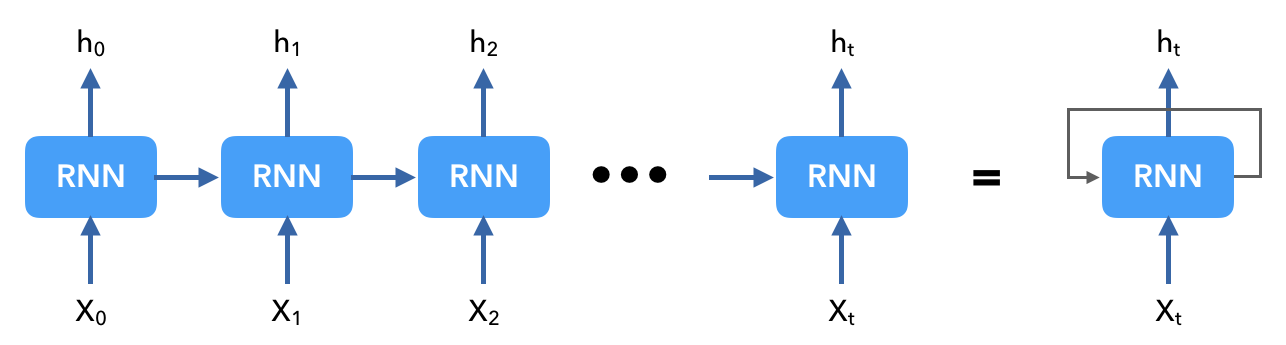
So far we've processed inputs as whole (ex. applying filters across the entire input to extract features) but we can also process our inputs sequentially. For example we can think of each token in our text as an event in time (timestep). We can process each timestep, one at a time, and predict the class after the last timestep (token) has been processed. This is very powerful because the model now has a meaningful way to account for the sequential order of tokens in our sequence and predict accordingly.
$$ \text{RNN forward pass for a single time step } X_t $$:
\[ h_t = tanh(W_{hh}h_{t-1} + W_{xh}X_t+b_h) \]
Variable
Description
\(N\)
batch size
\(E\)
embeddings dimension
\(H\)
# of hidden units
\(W_{hh}\)
RNN weights \(\in \mathbb{R}^{HXH}\)
\(h_{t-1}\)
previous timestep's hidden state \(\in in \mathbb{R}^{NXH}\)
\(W_{xh}\)
input weights \(\in \mathbb{R}^{EXH}\)
\(X_t\)
input at time step \(t \in \mathbb{R}^{NXE}\)
\(b_h\)
hidden units bias \(\in \mathbb{R}^{HX1}\)
\(h_t\)
output from RNN for timestep \(t\)
Objective:
Process sequential data by accounting for the current input and also what has been learned from previous inputs.
Advantages:
Account for order and previous inputs in a meaningful way.
Conditioned generation for generating sequences.
Disadvantages:
Each time step's prediction depends on the previous prediction so it's difficult to parallelize RNN operations.
Processing long sequences can yield memory and computation issues.
Interpretability is difficult but there are few techniques that use the activations from RNNs to see what parts of the inputs are processed.
Miscellaneous:
Architectural tweaks to make RNNs faster and interpretable is an ongoing area of research.
defset_seeds(seed=1234):"""Set seeds for reproducibility."""np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# multi-GPU
12
# Set seeds for reproducibilityset_seeds(seed=SEED)
12345678
# Set devicecuda=Truedevice=torch.device("cuda"if(torch.cuda.is_available()andcuda)else"cpu")torch.set_default_tensor_type("torch.FloatTensor")ifdevice.type=="cuda":torch.set_default_tensor_type("torch.cuda.FloatTensor")print(device)
cuda
Load data
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
Sharon Accepts Plan to Reduce Gaza Army Operation...
World
1
Internet Key Battleground in Wildlife Crime Fight
Sci/Tech
2
July Durable Good Orders Rise 1.7 Percent
Business
3
Growing Signs of a Slowing on Wall Street
Business
4
The New Faces of Reality TV
World
Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
['i', 'me', 'my', 'myself', 'we']
1 2 3 4 5 6 7 8 910111213141516171819
defpreprocess(text,stopwords=STOPWORDS):"""Conditional preprocessing on our text unique to our task."""# Lowertext=text.lower()# Remove stopwordspattern=re.compile(r"\b("+r"|".join(stopwords)+r")\b\s*")text=pattern.sub("",text)# Remove words in parenthesistext=re.sub(r"\([^)]*\)","",text)# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)text=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()returntext
123
# Sampletext="Great week for the NYSE!"preprocess(text=text)
great week nyse
1234
# Apply to dataframepreprocessed_df=df.copy()preprocessed_df.title=preprocessed_df.title.apply(preprocess)print(f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says
sharon accepts plan reduce gaza army operation haaretz says
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
classLabelEncoder(object):"""Label encoder for tag labels."""def__init__(self,class_to_index={}):self.class_to_index=class_to_indexor{}# mutable defaults ;)self.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())def__len__(self):returnlen(self.class_to_index)def__str__(self):returnf"<LabelEncoder(num_classes={len(self)})>"deffit(self,y):classes=np.unique(y)fori,class_inenumerate(classes):self.class_to_index[class_]=iself.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())returnselfdefencode(self,y):encoded=np.zeros((len(y)),dtype=int)fori,iteminenumerate(y):encoded[i]=self.class_to_index[item]returnencodeddefdecode(self,y):classes=[]fori,iteminenumerate(y):classes.append(self.index_to_class[item])returnclassesdefsave(self,fp):withopen(fp,"w")asfp:contents={'class_to_index':self.class_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
classTokenizer(object):def__init__(self,char_level,num_tokens=None,pad_token="<PAD>",oov_token="<UNK>",token_to_index=None):self.char_level=char_levelself.separator=""ifself.char_levelelse" "ifnum_tokens:num_tokens-=2# pad + unk tokensself.num_tokens=num_tokensself.pad_token=pad_tokenself.oov_token=oov_tokenifnottoken_to_index:token_to_index={pad_token:0,oov_token:1}self.token_to_index=token_to_indexself.index_to_token={v:kfork,vinself.token_to_index.items()}def__len__(self):returnlen(self.token_to_index)def__str__(self):returnf"<Tokenizer(num_tokens={len(self)})>"deffit_on_texts(self,texts):ifnotself.char_level:texts=[text.split(" ")fortextintexts]all_tokens=[tokenfortextintextsfortokenintext]counts=Counter(all_tokens).most_common(self.num_tokens)self.min_token_freq=counts[-1][1]fortoken,countincounts:index=len(self)self.token_to_index[token]=indexself.index_to_token[index]=tokenreturnselfdeftexts_to_sequences(self,texts):sequences=[]fortextintexts:ifnotself.char_level:text=text.split(" ")sequence=[]fortokenintext:sequence.append(self.token_to_index.get(token,self.token_to_index[self.oov_token]))sequences.append(np.asarray(sequence))returnsequencesdefsequences_to_texts(self,sequences):texts=[]forsequenceinsequences:text=[]forindexinsequence:text.append(self.index_to_token.get(index,self.oov_token))texts.append(self.separator.join([tokenfortokenintext]))returntextsdefsave(self,fp):withopen(fp,"w")asfp:contents={"char_level":self.char_level,"oov_token":self.oov_token,"token_to_index":self.token_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
Warning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Sample of tokensprint(take(5,tokenizer.token_to_index.items()))print(f"least freq token's freq: {tokenizer.min_token_freq}")# use this to adjust num_tokens
# Convert texts to sequences of indicesX_train=tokenizer.texts_to_sequences(X_train)X_val=tokenizer.texts_to_sequences(X_val)X_test=tokenizer.texts_to_sequences(X_test)preprocessed_text=tokenizer.sequences_to_texts([X_train[0]])[0]print("Text to indices:\n"f" (preprocessed) → {preprocessed_text}\n"f" (tokenized) → {X_train[0]}")
Text to indices:
(preprocessed) → china battles north korea nuclear talks
(tokenized) → [ 16 1491 285 142 114 24]
Padding
We'll need to do 2D padding to our tokenized text.
1234567
defpad_sequences(sequences,max_seq_len=0):"""Pad sequences to max length in sequence."""max_seq_len=max(max_seq_len,max(len(sequence)forsequenceinsequences))padded_sequences=np.zeros((len(sequences),max_seq_len))fori,sequenceinenumerate(sequences):padded_sequences[i][:len(sequence)]=sequencereturnpadded_sequences
classDataset(torch.utils.data.Dataset):def__init__(self,X,y):self.X=Xself.y=ydef__len__(self):returnlen(self.y)def__str__(self):returnf"<Dataset(N={len(self)})>"def__getitem__(self,index):X=self.X[index]y=self.y[index]return[X,len(X),y]defcollate_fn(self,batch):"""Processing on a batch."""# Get inputsbatch=np.array(batch)X=batch[:,0]seq_lens=batch[:,1]y=batch[:,2]# Pad inputsX=pad_sequences(sequences=X)# CastX=torch.LongTensor(X.astype(np.int32))seq_lens=torch.LongTensor(seq_lens.astype(np.int32))y=torch.LongTensor(y.astype(np.int32))returnX,seq_lens,ydefcreate_dataloader(self,batch_size,shuffle=False,drop_last=False):returntorch.utils.data.DataLoader(dataset=self,batch_size=batch_size,collate_fn=self.collate_fn,shuffle=shuffle,drop_last=drop_last,pin_memory=True)
1 2 3 4 5 6 7 8 9101112
# Create datasetstrain_dataset=Dataset(X=X_train,y=y_train)val_dataset=Dataset(X=X_val,y=y_val)test_dataset=Dataset(X=X_test,y=y_test)print("Datasets:\n"f" Train dataset:{train_dataset.__str__()}\n"f" Val dataset: {val_dataset.__str__()}\n"f" Test dataset: {test_dataset.__str__()}\n""Sample point:\n"f" X: {train_dataset[0][0]}\n"f" seq_len: {train_dataset[0][1]}\n"f" y: {train_dataset[0][2]}")
classTrainer(object):def__init__(self,model,device,loss_fn=None,optimizer=None,scheduler=None):# Set paramsself.model=modelself.device=deviceself.loss_fn=loss_fnself.optimizer=optimizerself.scheduler=schedulerdeftrain_step(self,dataloader):"""Train step."""# Set model to train modeself.model.train()loss=0.0# Iterate over train batchesfori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,targets=batch[:-1],batch[-1]self.optimizer.zero_grad()# Reset gradientsz=self.model(inputs)# Forward passJ=self.loss_fn(z,targets)# Define lossJ.backward()# Backward passself.optimizer.step()# Update weights# Cumulative Metricsloss+=(J.detach().item()-loss)/(i+1)returnlossdefeval_step(self,dataloader):"""Validation or test step."""# Set model to eval modeself.model.eval()loss=0.0y_trues,y_probs=[],[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,y_true=batch[:-1],batch[-1]z=self.model(inputs)# Forward passJ=self.loss_fn(z,y_true).item()# Cumulative Metricsloss+=(J-loss)/(i+1)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)y_trues.extend(y_true.cpu().numpy())returnloss,np.vstack(y_trues),np.vstack(y_probs)defpredict_step(self,dataloader):"""Prediction step."""# Set model to eval modeself.model.eval()y_probs=[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]z=self.model(inputs)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)returnnp.vstack(y_probs)deftrain(self,num_epochs,patience,train_dataloader,val_dataloader):best_val_loss=np.infforepochinrange(num_epochs):# Stepstrain_loss=self.train_step(dataloader=train_dataloader)val_loss,_,_=self.eval_step(dataloader=val_dataloader)self.scheduler.step(val_loss)# Early stoppingifval_loss<best_val_loss:best_val_loss=val_lossbest_model=self.model_patience=patience# reset _patienceelse:_patience-=1ifnot_patience:# 0print("Stopping early!")break# Loggingprint(f"Epoch: {epoch+1} | "f"train_loss: {train_loss:.5f}, "f"val_loss: {val_loss:.5f}, "f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "f"_patience: {_patience}")returnbest_model
Vanilla RNN
RNN
Inputs to RNNs are sequential like text or time-series.
12
BATCH_SIZE=64EMBEDDING_DIM=100
123456
# Inputsequence_size=8# words per inputx=torch.rand((BATCH_SIZE,sequence_size,EMBEDDING_DIM))seq_lens=torch.randint(high=sequence_size,size=(BATCH_SIZE,))print(x.shape)print(seq_lens.shape)
torch.Size([64, 8, 100])
torch.Size([1, 64])
$$ \text{RNN forward pass for a single time step } X_t $$:
\[ h_t = tanh(W_{hh}h_{t-1} + W_{xh}X_t+b_h) \]
Variable
Description
\(N\)
batch size
\(E\)
embeddings dimension
\(H\)
# of hidden units
\(W_{hh}\)
RNN weights \(\in \mathbb{R}^{HXH}\)
\(h_{t-1}\)
previous timestep's hidden state \(\in in \mathbb{R}^{NXH}\)
\(W_{xh}\)
input weights \(\in \mathbb{R}^{EXH}\)
\(X_t\)
input at time step \(t \in \mathbb{R}^{NXE}\)
\(b_h\)
hidden units bias \(\in \mathbb{R}^{HX1}\)
\(h_t\)
output from RNN for timestep \(t\)
At the first time step, the previous hidden state \(h_{t-1}\) can either be a zero vector (unconditioned) or initialized (conditioned). If we are conditioning the RNN, the first hidden state \(h_0\) can belong to a specific condition or we can concat the specific condition to the randomly initialized hidden vectors at each time step. More on this in the subsequent notebooks on RNNs.
# Forward pass through RNNx=x.permute(1,0,2)# RNN needs batch_size to be at dim 1# Loop through the inputs time stepshiddens=[]fortinrange(sequence_size):hidden_t=rnn_cell(x[t],hidden_t)hiddens.append(hidden_t)hiddens=torch.stack(hiddens)hiddens=hiddens.permute(1,0,2)# bring batch_size back to dim 0print(hiddens.size())
torch.Size([64, 8, 128])
123456
# We also could've used a more abstracted layerx=torch.rand((BATCH_SIZE,sequence_size,EMBEDDING_DIM))rnn=nn.RNN(EMBEDDING_DIM,RNN_HIDDEN_DIM,batch_first=True)out,h_n=rnn(x)# h_n is the last hidden stateprint("out: ",out.shape)print("h_n: ",h_n.shape)
In our model, we want to use the RNN's output after the last relevant token in the sentence is processed. The last relevant token doesn't refer the <PAD> tokens but to the last actual word in the sentence and its index is different for each input in the batch. This is why we included a seq_lens tensor in our batches.
12345678
defgather_last_relevant_hidden(hiddens,seq_lens):"""Extract and collect the last relevant hidden state based on the sequence length."""seq_lens=seq_lens.long().detach().cpu().numpy()-1out=[]forbatch_index,column_indexinenumerate(seq_lens):out.append(hiddens[batch_index,column_index])returntorch.stack(out)
12
# Get the last relevant hidden stategather_last_relevant_hidden(hiddens=out,seq_lens=seq_lens).squeeze(0).shape
torch.Size([64, 128])
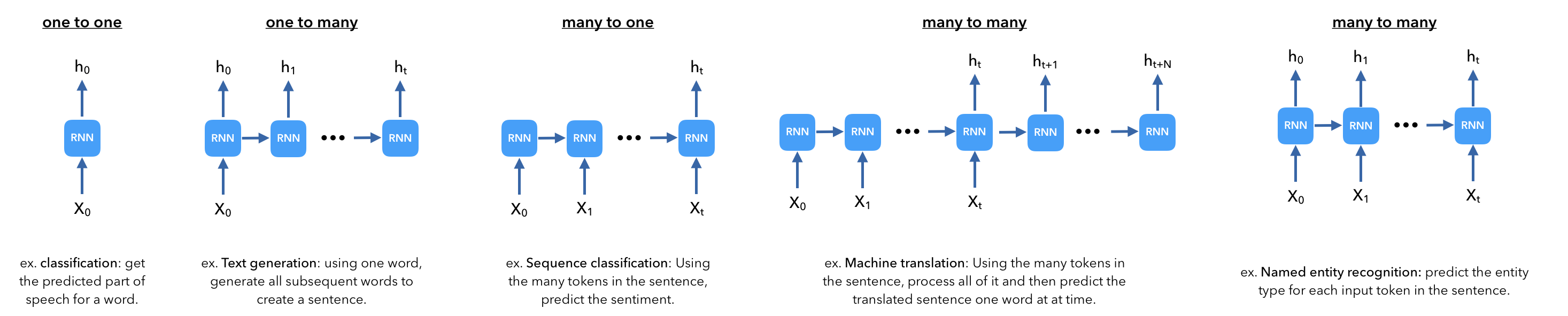
There are many different ways to use RNNs. So far we've processed our inputs one timestep at a time and we could either use the RNN's output at each time step or just use the final input timestep's RNN output. Let's look at a few other possibilities.
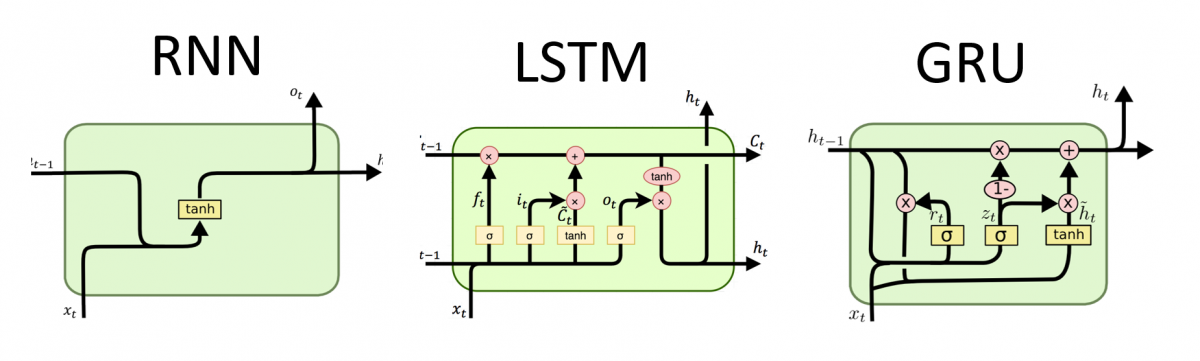
While our simple RNNs so far are great for sequentially processing our inputs, they have quite a few disadvantages. They commonly suffer from exploding or vanishing gradients as a result using the same set of weights (\(W_{xh}\) and \(W_{hh}\)) with each timestep's input. During backpropagation, this can cause gradients to explode (>1) or vanish (<1). If you multiply any number greater than 1 with itself over and over, it moves towards infinity (exploding gradients) and similarly, If you multiply any number less than 1 with itself over and over, it moves towards zero (vanishing gradients). To mitigate this issue, gated RNNs were devised to selectively retain information. If you're interested in learning more of the specifics, this post is a must-read.
There are two popular types of gated RNNs: Long Short-term Memory (LSTMs) units and Gated Recurrent Units (GRUs).
When deciding between LSTMs and GRUs, empirical performance is the best factor but in general GRUs offer similar performance with less complexity (less weights).
We can also have RNNs that process inputs from both directions (first token to last token and vice versa) and combine their outputs. This architecture is known as a bidirectional RNN.
Notice that the output for each sample at each timestamp has size 256 (double the RNN_HIDDEN_DIM). This is because this includes both the forward and backward directions from the BiRNN.
# Save artifactsdir=Path("gru")dir.mkdir(parents=True,exist_ok=True)label_encoder.save(fp=Path(dir,"label_encoder.json"))tokenizer.save(fp=Path(dir,'tokenizer.json'))torch.save(best_model.state_dict(),Path(dir,"model.pt"))withopen(Path(dir,'performance.json'),"w")asfp:json.dump(performance,indent=2,sort_keys=False,fp=fp)
Inference
12345678
defget_probability_distribution(y_prob,classes):"""Create a dict of class probabilities from an array."""results={}fori,class_inenumerate(classes):results[class_]=np.float64(y_prob[i])sorted_results={k:vfork,vinsorted(results.items(),key=lambdaitem:item[1],reverse=True)}returnsorted_results
# Dataloadertext="The final tennis tournament starts next week."X=tokenizer.texts_to_sequences([preprocess(text)])print(tokenizer.sequences_to_texts(X))y_filler=label_encoder.encode([label_encoder.classes[0]]*len(X))dataset=Dataset(X=X,y=y_filler)dataloader=dataset.create_dataloader(batch_size=batch_size)