📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Set up
First we'll import the NumPy and Pandas libraries and set seeds for reproducibility. We'll also download the dataset we'll be working with to disk.
12
importnumpyasnpimportpandasaspd
12
# Set seed for reproducibilitynp.random.seed(seed=1234)
Load data
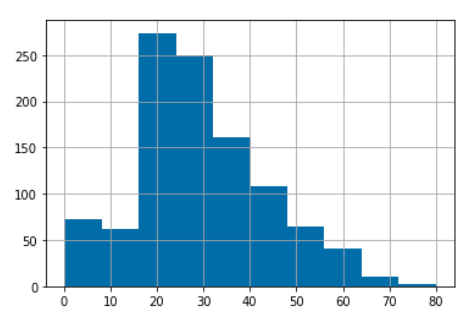
We're going to work with the Titanic dataset which has data on the people who embarked the RMS Titanic in 1912 and whether they survived the expedition or not. It's a very common and rich dataset which makes it very apt for exploratory data analysis with Pandas.
Let's load the data from the CSV file into a Pandas dataframe. The header=0 signifies that the first row (0th index) is a header row which contains the names of each column in our dataset.
123
# Read from CSV to Pandas DataFrameurl="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/titanic.csv"df=pd.read_csv(url,header=0)
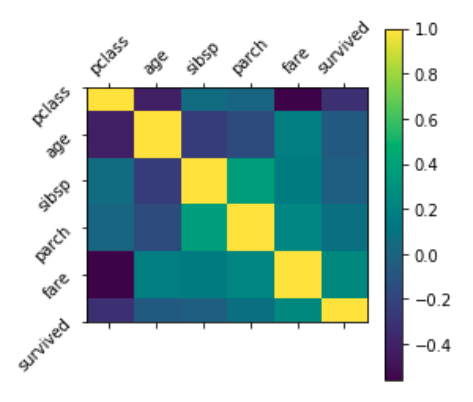
We can also get statistics across our features for certain groups. Here we wan to see the average of our continuous features based on whether the passenger survived or not.
We can use iloc to get rows or columns at particular positions in the dataframe.
12
# Selecting row 0df.iloc[0,:]
pclass 1
name Allen, Miss. Elisabeth Walton
sex female
age 29
sibsp 0
parch 0
ticket 24160
fare 211.338
cabin B5
embarked S
survived 1
Name: 0, dtype: object
12
# Selecting a specific valuedf.iloc[0,1]
'Allen, Miss. Elisabeth Walton'
Preprocessing
After exploring, we can clean and preprocess our dataset.
Be sure to check out our entire lesson focused on preprocessing in our MLOps course.
12
# Rows with at least one NaN valuedf[pd.isnull(df).any(axis=1)].head()
pclass
name
sex
age
sibsp
parch
ticket
fare
cabin
embarked
survived
9
1
Artagaveytia, Mr. Ramon
male
71.0
0
0
PC 17609
49.5042
NaN
C
0
13
1
Barber, Miss. Ellen "Nellie"
female
26.0
0
0
19877
78.8500
NaN
S
1
15
1
Baumann, Mr. John D
male
NaN
0
0
PC 17318
25.9250
NaN
S
0
23
1
Bidois, Miss. Rosalie
female
42.0
0
0
PC 17757
227.5250
NaN
C
1
25
1
Birnbaum, Mr. Jakob
male
25.0
0
0
13905
26.0000
NaN
C
0
1234
# Drop rows with Nan valuesdf=df.dropna()# removes rows with any NaN valuesdf=df.reset_index()# reset's row indexes in case any rows were droppeddf.head()
index
pclass
name
sex
age
sibsp
parch
ticket
fare
cabin
embarked
survived
0
0
1
Allen, Miss. Elisabeth Walton
female
29.0000
0
0
24160
211.3375
B5
S
1
1
1
1
Allison, Master. Hudson Trevor
male
0.9167
1
2
113781
151.5500
C22 C26
S
1
2
2
1
Allison, Miss. Helen Loraine
female
2.0000
1
2
113781
151.5500
C22 C26
S
0
3
3
1
Allison, Mr. Hudson Joshua Creighton
male
30.0000
1
2
113781
151.5500
C22 C26
S
0
4
4
1
Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
female
25.0000
1
2
113781
151.5500
C22 C26
S
0
123
# Dropping multiple columnsdf=df.drop(["name","cabin","ticket"],axis=1)# we won't use text features for our initial basic modelsdf.head()
We're now going to use feature engineering to create a column called family_size. We'll first define a function called get_family_size that will determine the family size using the number of parents and siblings.
1234
# Lambda expressions to create new featuresdefget_family_size(sibsp,parch):family_size=sibsp+parchreturnfamily_size
Once we define the function, we can use lambda to apply that function on each row (using the numbers of siblings and parents in each row to determine the family size for each row).
Feature engineering can be done in collaboration with domain experts that can guide us on what features to engineer and use.
Save data
Finally, let's save our preprocessed data into a new CSV file to use later.
12
# Saving dataframe to CSVdf.to_csv("processed_titanic.csv",index=False)
12
# See the saved file!ls-l
total 96
-rw-r--r-- 1 root root 6975 Dec 3 17:36 processed_titanic.csv
drwxr-xr-x 1 root root 4096 Nov 21 16:30 sample_data
-rw-r--r-- 1 root root 85153 Dec 3 17:36 titanic.csv
Scaling
When working with very large datasets, our Pandas DataFrames can become very large and it can be very slow or impossible to operate on them. This is where packages that can distribute workloads or run on more efficient hardware can come in handy.
Dask: parallel computing to scale packages like Numpy, Pandas and scikit-learn on one/multiple machines.
cuDF: efficient dataframe loading and computation on a GPU.
And, of course, we can combine these together (Dask-cuDF) to operate on partitions of a dataframe on the GPU.
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Pandas - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}