Machine Learning Systems Design

Subscribe to our newsletter
📬 Receive new lessons straight to your inbox (once a month) and join 40K+ developers in learning how to responsibly deliver value with ML.
Overview
In the previous lesson, we covered the product design process for our ML application. In this lesson, we'll cover the systems design process where we'll learn how to design the ML system that will address our product objectives.
Template
The template below is designed to guide machine learning product development. It involves both the product and systems design aspects of our application:
Product design (What & Why) → Systems design (How)
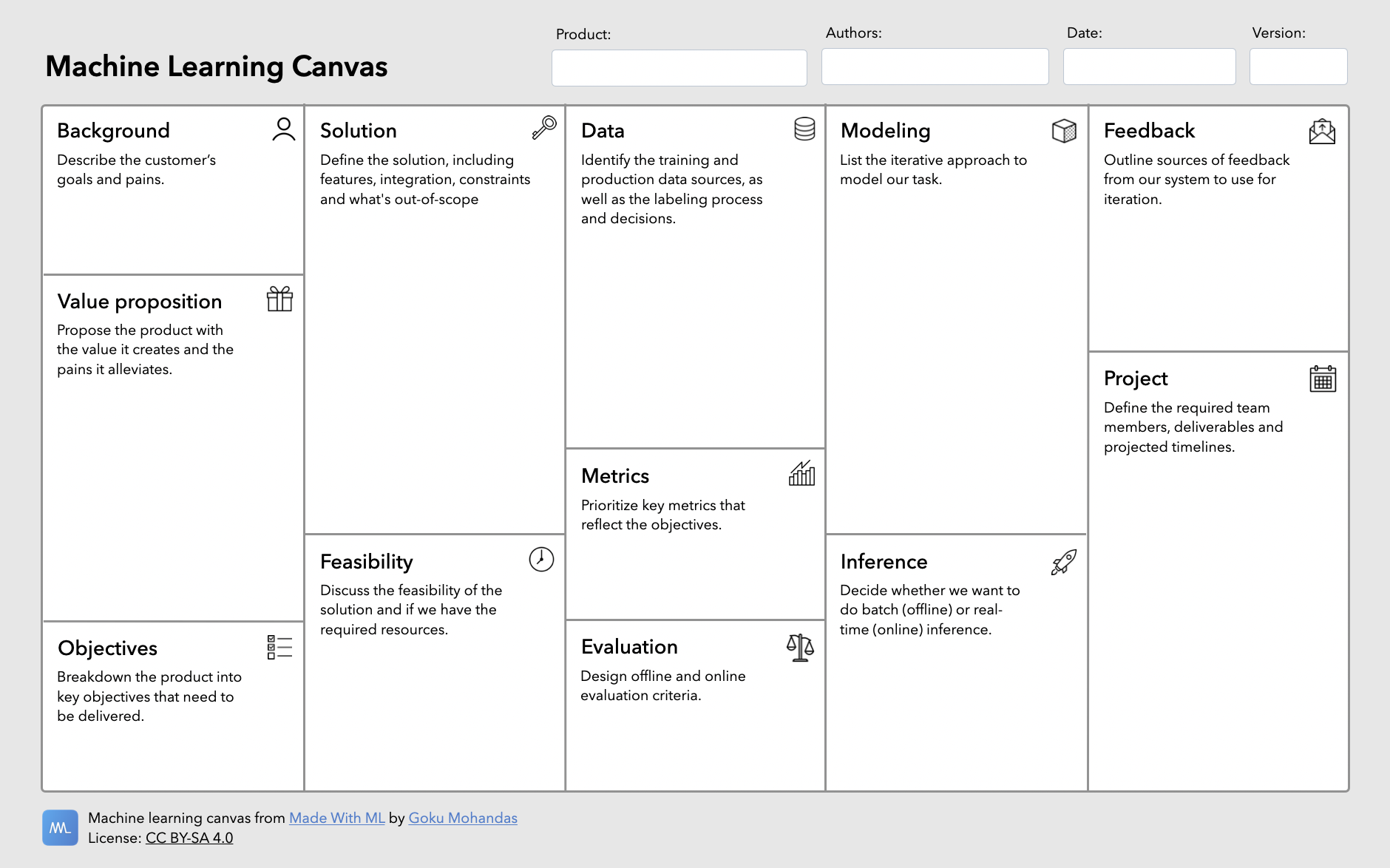
👉 Download a PDF of the ML canvas to use for your own products → ml-canvas.pdf (right click the link and hit "Save Link As...")
Systems design
How can we engineer our approach for building the product? We need to account for everything from data ingestion to model serving.
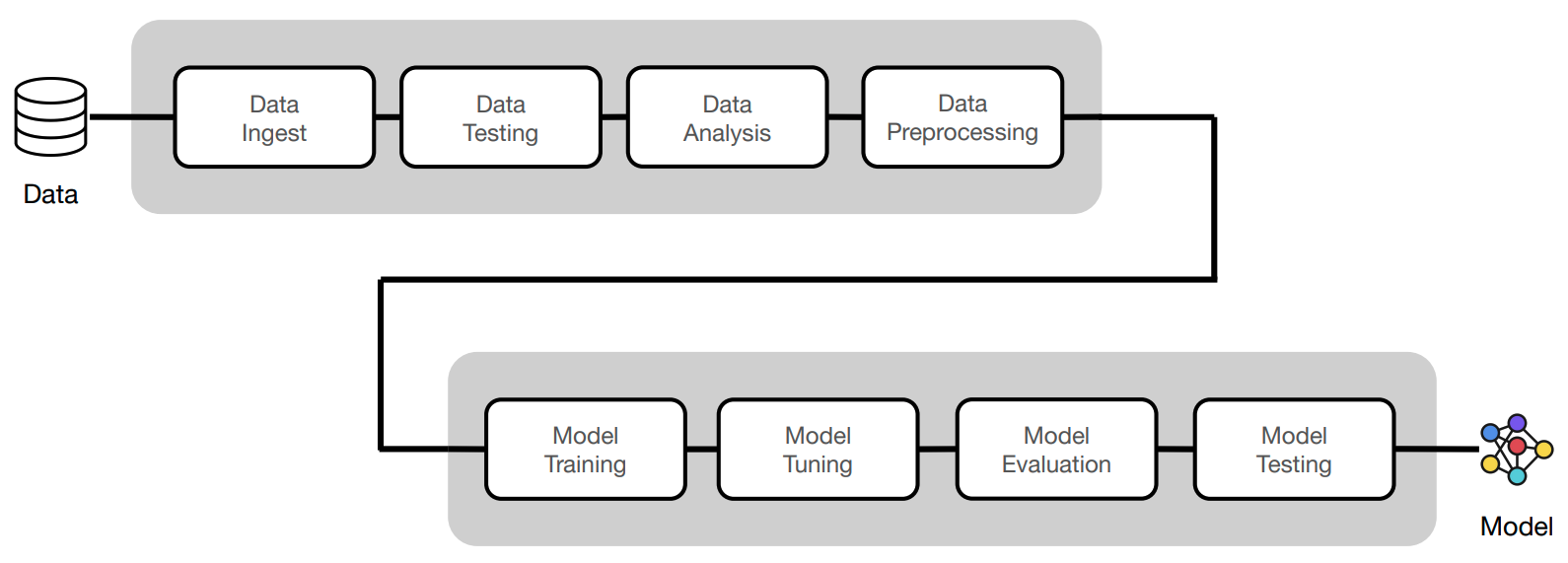
Data
Describe the training and production (batches/streams) sources of data.
Our task
- training:
- access to training data and testing (holdout) data.
- was there sampling of any kind applied to create this dataset?
- are we introducing any data leaks?
- production:
| Assumption | Reality | Reason |
|---|---|---|
| All of our incoming data is only machine learning related (no spam). | We would need a filter to remove spam content that's not ML related. | To simplify our ML task, we will assume all the data is ML content. |
Labeling
Describe the labeling process (ingestions, QA, etc.) and how we decided on the features and labels.
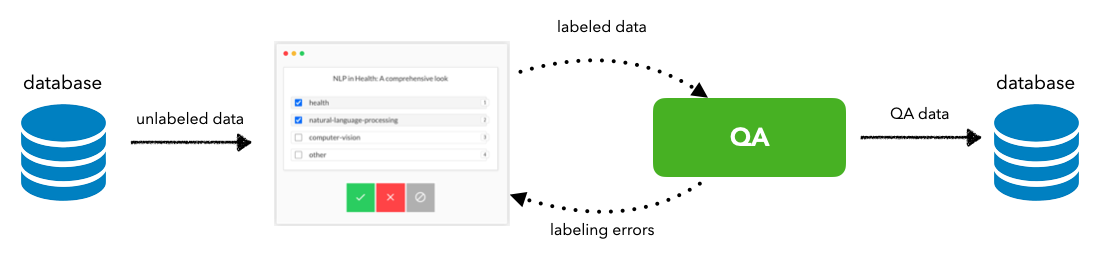
Our task
Labels: categories of machine learning (for simplification, we've restricted the label space to the following tags: natural-language-processing, computer-vision, mlops and other).
Features: text features (title and description) that describe the content.
| Assumption | Reality | Reason |
|---|---|---|
| Content can only belong to one category (multiclass). | Content can belong to more than one category (multilabel). | For simplicity and many libraries don't support or complicate multilabel scenarios. |
Metrics
One of the hardest challenges with ML systems is tying our core objectives, many of which may be qualitative, with quantitative metrics that our model can optimize towards.
Our task
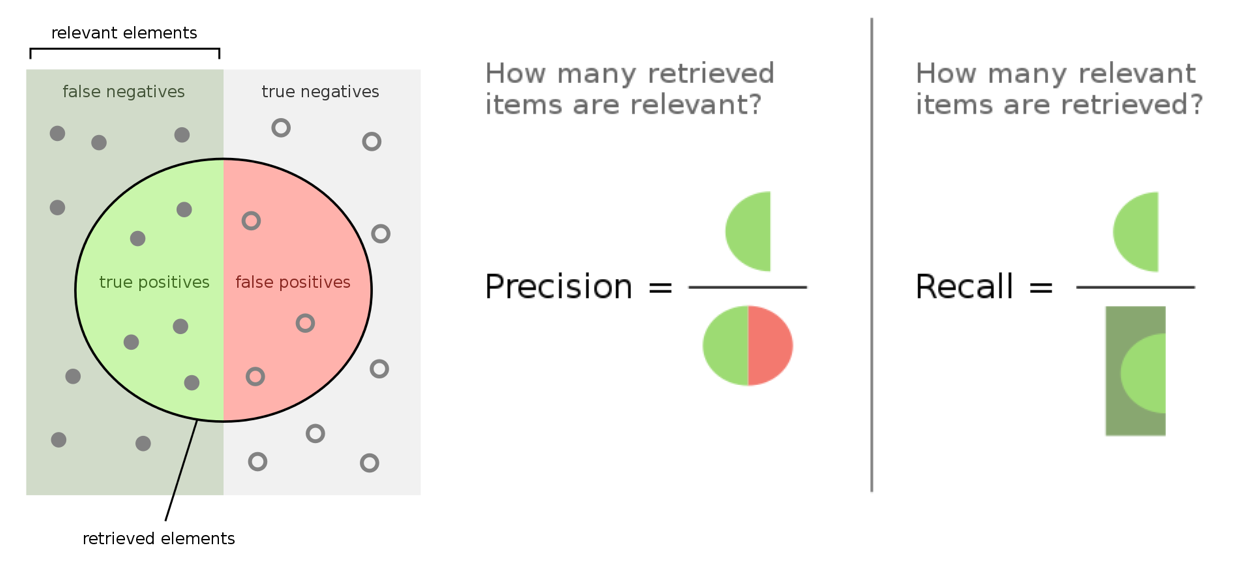
For our task, we want to have both high precision and recall, so we'll optimize for f1 score (weighted combination of precision and recall). We'll determine these metrics for the overall dataset, as well as specific classes or slices of data.
- True positives (TP): we correctly predicted class X.
- False positives (FP): we incorrectly predicted class X but it was another class.
- True negatives (TN): we correctly predicted that it's wasn't the class X.
- False negatives (FN): we incorrectly predicted that it wasn't the class X but it was.
What are our priorities
How do we decide which metrics to prioritize?
Show answer
It entirely depends on the specific task. For example, in an email spam detector, precision is very important because it's better than we some spam then completely miss an important email. Overtime, we need to iterate on our solution so all evaluation metrics improve but it's important to know which one's we can't comprise on from the get-go.
Evaluation
Once we have our metrics defined, we need to think about when and how we'll evaluate our model.
Offline evaluation
Offline evaluation requires a gold standard holdout dataset that we can use to benchmark all of our models.
Our task
We'll be using this holdout dataset for offline evaluation. We'll also be creating slices of data that we want to evaluate in isolation.
Online evaluation
Online evaluation ensures that our model continues to perform well in production and can be performed using labels or, in the event we don't readily have labels, proxy signals.
Our task
- manually label a subset of incoming data to evaluate periodically.
- asking the initial set of users viewing a newly categorized content if it's correctly classified.
- allow users to report misclassified content by our model.
It's important that we measure real-time performance before committing to replace our existing version of the system.
- Internal canary rollout, monitoring for proxy/actual performance, etc.
- Rollout to the larger internal team for more feedback.
- A/B rollout to a subset of the population to better understand UX, utility, etc.
Not all releases have to be high stakes and external facing. We can always include internal releases, gather feedback and iterate until we’re ready to increase the scope.
Modeling
While the specific methodology we employ can differ based on the problem, there are core principles we always want to follow:
- End-to-end utility: the end result from every iteration should deliver minimum end-to-end utility so that we can benchmark iterations against each other and plug-and-play with the system.
- Manual before ML: try to see how well a simple rule-based system performs before moving onto more complex ones.
- Augment vs. automate: allow the system to supplement the decision making process as opposed to making the actual decision.
- Internal vs. external: not all early releases have to be end-user facing. We can use early versions for internal validation, feedback, data collection, etc.
- Thorough: every approach needs to be well tested (code, data + models) and evaluated, so we can objectively benchmark different approaches.
Our task
- creating a gold-standard labeled dataset that is representative of the problem space.
- rule-based text matching approaches to categorize content.
- predict labels (probabilistic) from content title and description.
| Assumption | Reality | Reason |
|---|---|---|
| Solution needs to involve ML due to unstructured data and ineffectiveness of rule-based systems for this task. | An iterative approach where we start with simple rule-based solutions and slowly add complexity. | This course is about responsibly delivering value with ML, so we'll jump to it right away. |
Utility in starting simple
Some of the earlier, simpler, approaches may not deliver on a certain performance objective. What are some advantages of still starting simple?
Show answer
- get internal feedback on end-to-end utility.
- perform A/B testing to understand UI/UX design.
- deployed locally to start generating more data required for more complex approaches.
Inference
Once we have a model we're satisfied with, we need to think about whether we want to perform batch (offline) or real-time (online) inference.
Batch inference
We can use our models to make batch predictions on a finite set of inputs which are then written to a database for low latency inference. When a user or downstream service makes an inference request, cached results from the database are returned. In this scenario, our trained model can directly be loaded and used for inference in the code. It doesn't have to be served as a separate service.
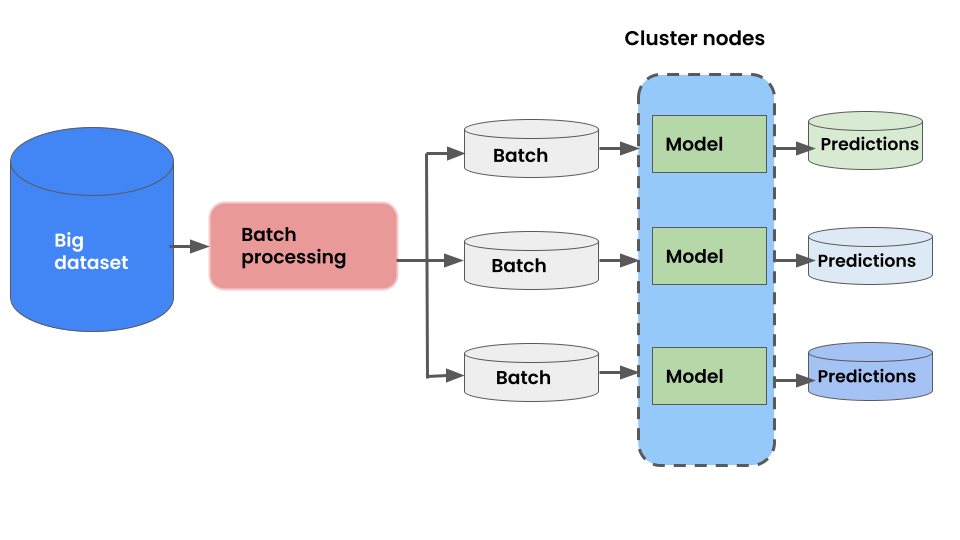
- ✅ generate and cache predictions for very fast inference for users.
- ✅ the model doesn't need to be spun up as it's own service since it's never used in real-time.
- ❌ predictions can become stale if user develops new interests that aren’t captured by the old data that the current predictions are based on.
Batch serving tasks
What are some tasks where batch serving is ideal?
Show answer
Recommend content that existing users will like based on their viewing history. However, new users may just receive some generic recommendations based on their explicit interests until we process their history the next day. And even if we're not doing batch serving, it might still be useful to cache very popular sets of input features (ex. combination of explicit interests leads to certain recommended content) so that we can serve those predictions faster.
Online inference
We can also serve real-time predictions where input features are fed to the model to retrieve predictions. In this scenario, our model will need to be served as a separate service (ex. api endpoint) that can handle incoming requests.

- ✅ can yield more up-to-date predictions which may yield a more meaningful user experience, etc.
- ❌ requires managed microservices to handle request traffic.
- ❌ requires real-time monitoring since input space in unbounded, which could yield erroneous predictions.
Online inference tasks
In our example task for batch inference above, how can online inference significantly improve content recommendations?
Show answer
With batch processing, we generate content recommendations for users offline using their history. These recommendations won't change until we process the batch the next day using the updated user features. But what is the user's taste significantly changes during the day (ex. user is searching for horror movies to watch). With real-time serving, we can use these recent features to recommend highly relevant content based on the immediate searches.
Our task
For our task, we'll be serving our model as a separate service to handle real-time requests. We want to be able to perform online inference so that we can quickly categorize ML content as they become available. However, we will also demonstrate how to do batch inference for the sake of completeness.
Feedback
How do we receive feedback on our system and incorporate it into the next iteration? This can involve both human-in-the-loop feedback as well as automatic feedback via monitoring, etc.
Our task
- enforce human-in-loop checks when there is low confidence in classifications.
- allow users to report issues related to misclassification.
Always return to the value proposition
While it's important to iterate and optimize on our models, it's even more important to ensure that our ML systems are actually making an impact. We need to constantly engage with our users to iterate on why our ML system exists and how it can be made better.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
To cite this content, please use:
1 2 3 4 5 6 | |