📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
Our goal is to learn a linear model \(\hat{y}\) that models \(y\) given \(X\) using weights \(W\) and bias \(b\):
\[ \hat{y} = XW + b \]
Variable
Description
\(N\)
total numbers of samples
\(\hat{y}\)
predictions \(\in \mathbb{R}^{NX1}\)
\(X\)
inputs \(\in \mathbb{R}^{NXD}\)
\(W\)
weights \(\in \mathbb{R}^{DX1}\)
\(b\)
bias \(\in \mathbb{R}^{1}\)
Objective:
Use inputs \(X\) to predict the output \(\hat{y}\) using a linear model. The model will be a line of best fit that minimizes the distance between the predicted (model's output) and target (ground truth) values. Training data \((X, y)\) is used to train the model and learn the weights \(W\) using gradient descent.
Advantages:
Computationally simple.
Highly interpretable.
Can account for continuous and categorical features.
Disadvantages:
The model will perform well only when the data is linearly separable (for classification).
Miscellaneous:
You can also use linear regression for binary classification tasks where if the predicted continuous value is above a threshold, it belongs to a certain class. But we will cover better techniques for classification in future lessons and will focus on linear regression for continuous regression tasks only.
Generate data
We're going to generate some simple dummy data to apply linear regression on. It's going to create roughly linear data (y = 3.5X + noise); the random noise is added to create realistic data that doesn't perfectly align in a line. Our goal is to have the model converge to a similar linear equation (there will be slight variance since we added some noise).
# Set seed for reproducibilitynp.random.seed(SEED)
1234567
# Generate synthetic datadefgenerate_data(num_samples):"""Generate dummy data for linear regression."""X=np.array(range(num_samples))random_noise=np.random.uniform(-10,20,size=num_samples)y=3.5*X+random_noise# add some noisereturnX,y
1234
# Generate random (linear) dataX,y=generate_data(num_samples=NUM_SAMPLES)data=np.vstack([X,y]).Tprint(data[:5])
Now that we have our data prepared, we'll first implement linear regression using just NumPy. This will let us really understand the underlying operations.
Split data
Since our task is a regression task, we will randomly split our dataset into three sets: train, validation and test data splits.
train: used to train our model.
val : used to validate our model's performance during training.
test: used to do an evaluation of our fully trained model.
Be sure to check out our entire lesson focused on properlysplitting data in our MLOps course.
# Determine means and stdsX_mean=np.mean(X_train)X_std=np.std(X_train)y_mean=np.mean(y_train)y_std=np.std(y_train)
We need to treat the validation and test sets as if they were hidden datasets. So we only use the train set to determine the mean and std to avoid biasing our training process.
# Check (means should be ~0 and std should be ~1)# Check (means should be ~0 and std should be ~1)print(f"mean: {np.mean(X_test,axis=0)[0]:.1f}, std: {np.std(X_test,axis=0)[0]:.1f}")print(f"mean: {np.mean(y_test,axis=0)[0]:.1f}, std: {np.std(y_test,axis=0)[0]:.1f}")
mean: -0.4, std: 0.9
mean: -0.3, std: 1.0
Weights
Our goal is to learn a linear model \(\hat{y}\) that models \(y\) given \(X\) using weights \(W\) and bias \(b\) → \(\hat{y} = XW + b\)
Step 1: Randomly initialize the model's weights \(W\).
12
INPUT_DIM=X_train.shape[1]# X is 1-dimensionalOUTPUT_DIM=y_train.shape[1]# y is 1-dimensional
12345
# Initialize random weightsW=0.01*np.random.randn(INPUT_DIM,OUTPUT_DIM)b=np.zeros((1,1))print(f"W: {W.shape}")print(f"b: {b.shape}")
W: (1, 1)
b: (1, 1)
Model
Step 2: Feed inputs \(X\) into the model to receive the predictions \(\hat{y}\)
Step 3: Compare the predictions \(\hat{y}\) with the actual target values \(y\) using the objective (cost) function to determine the loss \(J\). A common objective function for linear regression is mean squared error (MSE). This function calculates the difference between the predicted and target values and squares it.
The gradient is the derivative, or the rate of change of a function. It's a vector that points in the direction of greatest increase of a function. For example the gradient of our loss function (\(J\)) with respect to our weights (\(W\)) will tell us how to change \(W\) so we can maximize \(J\). However, we want to minimize our loss so we subtract the gradient from \(W\).
Update weights
Step 5: Update the weights \(W\) using a small learning rate \(\alpha\).
\[ W = W - \alpha\frac{\partial{J}}{\partial{W}} \]
\[ b = b - \alpha\frac{\partial{J}}{\partial{b}} \]
The learning rate \(\alpha\) is a way to control how much we update the weights by. If we choose a small learning rate, it may take a long time for our model to train. However, if we choose a large learning rate, we may overshoot and our training will never converge. The specific learning rate depends on our data and the type of models we use but it's typically good to explore in the range of \([1e^{-8}, 1e^{-1}]\). We'll explore learning rate update strategies in later lessons.
Training
Step 6: Repeat steps 2 - 5 to minimize the loss and train the model.
1
NUM_EPOCHS=100
1 2 3 4 5 6 7 8 9101112131415161718192021222324
# Initialize random weightsW=0.01*np.random.randn(INPUT_DIM,OUTPUT_DIM)b=np.zeros((1,))# Training loopforepoch_numinrange(NUM_EPOCHS):# Forward pass [NX1] · [1X1] = [NX1]y_pred=np.dot(X_train,W)+b# Lossloss=(1/len(y_train))*np.sum((y_train-y_pred)**2)# Show progressifepoch_num%10==0:print(f"Epoch: {epoch_num}, loss: {loss:.3f}")# BackpropagationdW=-(2/N)*np.sum((y_train-y_pred)*X_train)db=-(2/N)*np.sum((y_train-y_pred)*1)# Update weightsW+=-LEARNING_RATE*dWb+=-LEARNING_RATE*db
To keep the code simple, we're not calculating and displaying the validation loss after each epoch here. But in later lessons, the performance on the validation set will be crucial in influencing the learning process (learning rate, when to stop training, etc.).
Evaluation
Now we're ready to see how well our trained model will perform on our test (hold-out) data split. This will be our best measure on how well the model would perform on the real world, given that our dataset's distribution is close to unseen data.
# Train and test MSEtrain_mse=np.mean((y_train-pred_train)**2)test_mse=np.mean((y_test-pred_test)**2)print(f"train_MSE: {train_mse:.2f}, test_MSE: {test_mse:.2f}")
train_MSE: 0.03, test_MSE: 0.01
1 2 3 4 5 6 7 8 910111213141516171819
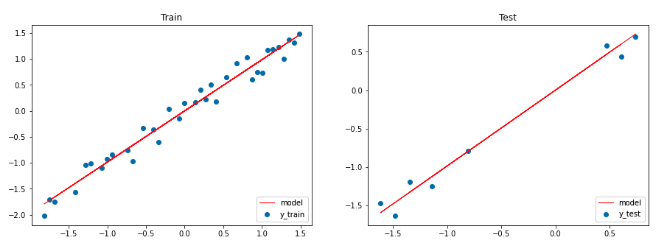
# Figure sizeplt.figure(figsize=(15,5))# Plot train dataplt.subplot(1,2,1)plt.title("Train")plt.scatter(X_train,y_train,label="y_train")plt.plot(X_train,pred_train,color="red",linewidth=1,linestyle="-",label="model")plt.legend(loc="lower right")# Plot test dataplt.subplot(1,2,2)plt.title("Test")plt.scatter(X_test,y_test,label='y_test')plt.plot(X_test,pred_test,color="red",linewidth=1,linestyle="-",label="model")plt.legend(loc="lower right")# Show plotsplt.show()
Interpretability
Since we standardized our inputs and outputs, our weights were fit to those standardized values. So we need to unstandardize our weights so we can compare it to our true weight (3.5).
This time we'll use scikit-learn's StandardScaler to standardize our data.
1
fromsklearn.preprocessingimportStandardScaler
123
# Standardize the data (mean=0, std=1) using training dataX_scaler=StandardScaler().fit(X_train)y_scaler=StandardScaler().fit(y_train)
1234567
# Apply scaler on training and test dataX_train=X_scaler.transform(X_train)y_train=y_scaler.transform(y_train).ravel().reshape(-1,1)X_val=X_scaler.transform(X_val)y_val=y_scaler.transform(y_val).ravel().reshape(-1,1)X_test=X_scaler.transform(X_test)y_test=y_scaler.transform(y_test).ravel().reshape(-1,1)
123
# Check (means should be ~0 and std should be ~1)print(f"mean: {np.mean(X_test,axis=0)[0]:.1f}, std: {np.std(X_test,axis=0)[0]:.1f}")print(f"mean: {np.mean(y_test,axis=0)[0]:.1f}, std: {np.std(y_test,axis=0)[0]:.1f}")
mean: -0.3, std: 0.7
mean: -0.3, std: 0.6
Weights
We will be using PyTorch's Linear layers in our MLP implementation. These layers will act as out weights (and biases).
\[ z = XW \]
1
fromtorchimportnn
12345
# InputsN=3# num samplesx=torch.randn(N,INPUT_DIM)print(x.shape)print(x.numpy())
When we implemented linear regression with just NumPy, we used batch gradient descent to update our weights (used entire training set). But there are actually many different gradient descent optimization algorithms to choose from and it depends on the situation. However, the ADAM optimizer has become a standard algorithm for most cases.
# Convert data to tensorsX_train=torch.Tensor(X_train)y_train=torch.Tensor(y_train)X_val=torch.Tensor(X_val)y_val=torch.Tensor(y_val)X_test=torch.Tensor(X_test)y_test=torch.Tensor(y_test)
1 2 3 4 5 6 7 8 910111213141516171819
# Trainingforepochinrange(NUM_EPOCHS):# Forward passy_pred=model(X_train)# Lossloss=loss_fn(y_pred,y_train)# Zero all gradientsoptimizer.zero_grad()# Backward passloss.backward()# Update weightsoptimizer.step()ifepoch%20==0:print(f"Epoch: {epoch} | loss: {loss:.2f}")
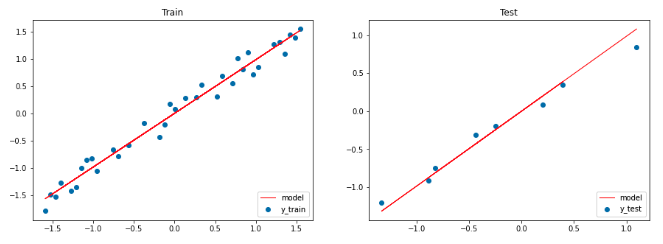
Since we only have one feature, it's easy to visually inspect the model.
1 2 3 4 5 6 7 8 910111213141516171819
# Figure sizeplt.figure(figsize=(15,5))# Plot train dataplt.subplot(1,2,1)plt.title("Train")plt.scatter(X_train,y_train,label="y_train")plt.plot(X_train,pred_train.detach().numpy(),color="red",linewidth=1,linestyle="-",label="model")plt.legend(loc="lower right")# Plot test dataplt.subplot(1,2,2)plt.title("Test")plt.scatter(X_test,y_test,label='y_test')plt.plot(X_test,pred_test.detach().numpy(),color="red",linewidth=1,linestyle="-",label="model")plt.legend(loc="lower right")# Show plotsplt.show()
Inference
After training a model, we can use it to predict on new data.
1234
# Feed in your own inputssample_indices=[10,15,25]X_infer=np.array(sample_indices,dtype=np.float32)X_infer=torch.Tensor(X_scaler.transform(X_infer.reshape(-1,1)))
Recall that we need to unstandardize our predictions.
Linear regression offers the great advantage of being highly interpretable. Each feature has a coefficient which signifies its importance/impact on the output variable y. We can interpret our coefficient as follows: by increasing X by 1 unit, we increase y by \(W\) (~3.65) units.
Regularization helps decrease overfitting. Below is L2 regularization (ridge regression). There are many forms of regularization but they all work to reduce overfitting in our models. With L2 regularization, we are penalizing large weight values by decaying them because having large weights will lead to preferential bias with the respective inputs and we want the model to work with all the inputs and not just a select few. There are also other types of regularization like L1 (lasso regression) which is useful for creating sparse models where some feature coefficients are zeroed out, or elastic which combines L1 and L2 penalties.
Regularization is not just for linear regression. You can use it to regularize any model's weights including the ones we will look at in future lessons.
Regularization didn't make a difference in performance with this specific example because our data is generated from a perfect linear equation but for large realistic data, regularization can help our model generalize well.
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Linear regression - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}