📬 Receive new lessons straight to your inbox (once a month) and join 40K+
developers in learning how to responsibly deliver value with ML.
Overview
While one-hot encoding allows us to preserve the structural information, it does poses two major disadvantages.
linearly dependent on the number of unique tokens in our vocabulary, which is a problem if we're dealing with a large corpus.
representation for each token does not preserve any relationship with respect to other tokens.
In this notebook, we're going to motivate the need for embeddings and how they address all the shortcomings of one-hot encoding. The main idea of embeddings is to have fixed length representations for the tokens in a text regardless of the number of tokens in the vocabulary. With one-hot encoding, each token is represented by an array of size vocab_size, but with embeddings, each token now has the shape embed_dim. The values in the representation will are not fixed binary values but rather, changing floating points allowing for fine-grained learned representations.
Objectives:
Represent tokens in text that capture the intrinsic semantic relationships.
Advantages:
Low-dimensionality while capturing relationships.
Interpretable token representations
Disadvantages:
Can be computationally intensive to precompute.
Miscellaneous:
There are lot's of pretrained embeddings to choose from but you can also train your own from scratch.
Learning embeddings
We can learn embeddings by creating our models in PyTorch but first, we're going to use a library that specializes in embeddings and topic modeling called Gensim.
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
1
SEED=1234
12
# Set seed for reproducibilitynp.random.seed(SEED)
12345
# Split text into sentencestokenizer=nltk.data.load("tokenizers/punkt/english.pickle")book=urllib.request.urlopen(url="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/harrypotter.txt")sentences=tokenizer.tokenize(str(book.read()))print(f"{len(sentences)} sentences")
12443 sentences
1 2 3 4 5 6 7 8 9101112131415
defpreprocess(text):"""Conditional preprocessing on our text."""# Lowertext=text.lower()# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)text=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()# Separate into word tokenstext=text.split(" ")returntext
Snape nodded, but did not elaborate.
['snape', 'nodded', 'but', 'did', 'not', 'elaborate']
But how do we learn the embeddings the first place? The intuition behind embeddings is that the definition of a token doesn't depend on the token itself but on its context. There are several different ways of doing this:
Given the word in the context, predict the target word (CBOW - continuous bag of words).
Given the target word, predict the context word (skip-gram).
Given a sequence of words, predict the next word (LM - language modeling).
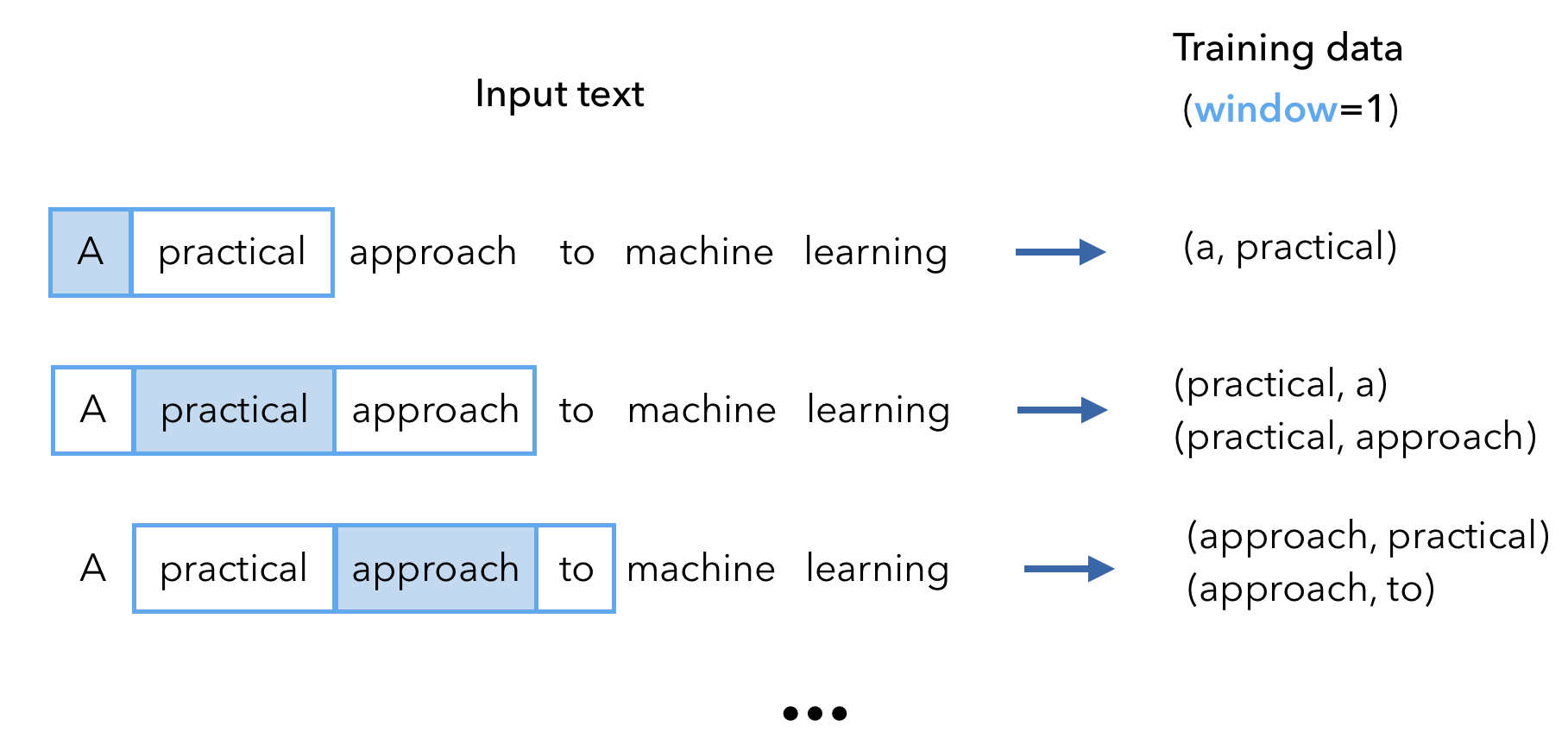
All of these approaches involve create data to train our model on. Every word in a sentence becomes the target word and the context words are determines by a window. In the image below (skip-gram), the window size is 2 (2 words to the left and right of the target word). We repeat this for every sentence in our corpus and this results in our training data for the unsupervised task. This in an unsupervised learning technique since we don't have official labels for contexts. The idea is that similar target words will appear with similar contexts and we can learn this relationship by repeatedly training our mode with (context, target) pairs.
We can learn embeddings using any of these approaches above and some work better than others. You can inspect the learned embeddings but the best way to choose an approach is to empirically validate the performance on a supervised task.
Word2Vec
When we have large vocabularies to learn embeddings for, things can get complex very quickly. Recall that the backpropagation with softmax updates both the correct and incorrect class weights. This becomes a massive computation for every backwards pass we do so a workaround is to use negative sampling which only updates the correct class and a few arbitrary incorrect classes (NEGATIVE_SAMPLING=20). We're able to do this because of the large amount of training data where we'll see the same word as the target class multiple times.
EMBEDDING_DIM=100WINDOW=5MIN_COUNT=3# Ignores all words with total frequency lower than thisSKIP_GRAM=1# 0 = CBOWNEGATIVE_SAMPLING=20
123456
# Super fast because of optimized C code under the hoodw2v=Word2Vec(sentences=sentences,size=EMBEDDING_DIM,window=WINDOW,min_count=MIN_COUNT,sg=SKIP_GRAM,negative=NEGATIVE_SAMPLING)print(w2v)
# Saving and loadingw2v.wv.save_word2vec_format("model.bin",binary=True)w2v=KeyedVectors.load_word2vec_format("model.bin",binary=True)
FastText
What happens when a word doesn't exist in our vocabulary? We could assign an UNK token which is used for all OOV (out of vocabulary) words or we could use FastText, which uses character-level n-grams to embed a word. This helps embed rare words, misspelled words, and also words that don't exist in our corpus but are similar to words in our corpus.
1
fromgensim.modelsimportFastText
12345
# Super fast because of optimized C code under the hoodft=FastText(sentences=sentences,size=EMBEDDING_DIM,window=WINDOW,min_count=MIN_COUNT,sg=SKIP_GRAM,negative=NEGATIVE_SAMPLING)print(ft)
FastText(vocab=4937, size=100, alpha=0.025)
12
# This word doesn't exist so the word2vec model will error outw2v.wv.most_similar(positive="scarring",topn=5)
12
# FastText will use n-grams to embed an OOV wordft.wv.most_similar(positive="scarring",topn=5)
# Save and loadingft.wv.save("model.bin")ft=KeyedVectors.load("model.bin")
Pretrained embeddings
We can learn embeddings from scratch using one of the approaches above but we can also leverage pretrained embeddings that have been trained on millions of documents. Popular ones include Word2Vec (skip-gram) or GloVe (global word-word co-occurrence). We can validate that these embeddings captured meaningful semantic relationships by confirming them.
# Unzip the file (may take ~3-5 minutes)resp=urlopen("http://nlp.stanford.edu/data/glove.6B.zip")zipfile=ZipFile(BytesIO(resp.read()))zipfile.namelist()
# Write embeddings to fileembeddings_file="glove.6B.{0}d.txt".format(EMBEDDING_DIM)zipfile.extract(embeddings_file)
/content/glove.6B.100d.txt
123456789
# Preview of the GloVe embeddings filewithopen(embeddings_file,"r")asfp:line=next(fp)values=line.split()word=values[0]embedding=np.asarray(values[1:],dtype='float32')print(f"word: {word}")print(f"embedding:\n{embedding}")print(f"embedding dim: {len(embedding)}")
# Save GloVe embeddings to local directory in word2vec formatword2vec_output_file="{0}.word2vec".format(embeddings_file)glove2word2vec(embeddings_file,word2vec_output_file)
(400000, 100)
12
# Load embeddings (may take a minute)glove=KeyedVectors.load_word2vec_format(word2vec_output_file,binary=False)
123
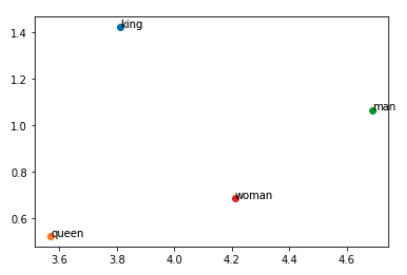
# (king - man) + woman = ?# king - man = ? - womanglove.most_similar(positive=["woman","king"],negative=["man"],topn=5)
defset_seeds(seed=1234):"""Set seeds for reproducibility."""np.random.seed(seed)random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# multi-GPU
12
# Set seeds for reproducibilityset_seeds(seed=SEED)
12345678
# Set devicecuda=Truedevice=torch.device("cuda"if(torch.cuda.is_available()andcuda)else"cpu")torch.set_default_tensor_type("torch.FloatTensor")ifdevice.type=="cuda":torch.set_default_tensor_type("torch.cuda.FloatTensor")print(device)
cuda
Load data
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
Sharon Accepts Plan to Reduce Gaza Army Operation...
World
1
Internet Key Battleground in Wildlife Crime Fight
Sci/Tech
2
July Durable Good Orders Rise 1.7 Percent
Business
3
Growing Signs of a Slowing on Wall Street
Business
4
The New Faces of Reality TV
World
Preprocessing
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
['i', 'me', 'my', 'myself', 'we']
1 2 3 4 5 6 7 8 910111213141516171819
defpreprocess(text,stopwords=STOPWORDS):"""Conditional preprocessing on our text unique to our task."""# Lowertext=text.lower()# Remove stopwordspattern=re.compile(r"\b("+r"|".join(stopwords)+r")\b\s*")text=pattern.sub("",text)# Remove words in parenthesistext=re.sub(r"\([^)]*\)","",text)# Spacing and filterstext=re.sub(r"([-;;.,!?<=>])",r" \1 ",text)text=re.sub("[^A-Za-z0-9]+"," ",text)# remove non alphanumeric charstext=re.sub(" +"," ",text)# remove multiple spacestext=text.strip()returntext
123
# Sampletext="Great week for the NYSE!"preprocess(text=text)
great week nyse
1234
# Apply to dataframepreprocessed_df=df.copy()preprocessed_df.title=preprocessed_df.title.apply(preprocess)print(f"{df.title.values[0]}\n\n{preprocessed_df.title.values[0]}")
Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says
sharon accepts plan reduce gaza army operation haaretz says
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
deftrain_val_test_split(X,y,train_size):"""Split dataset into data splits."""X_train,X_,y_train,y_=train_test_split(X,y,train_size=TRAIN_SIZE,stratify=y)X_val,X_test,y_val,y_test=train_test_split(X_,y_,train_size=0.5,stratify=y_)returnX_train,X_val,X_test,y_train,y_val,y_test
classLabelEncoder(object):"""Label encoder for tag labels."""def__init__(self,class_to_index={}):self.class_to_index=class_to_indexor{}# mutable defaults ;)self.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())def__len__(self):returnlen(self.class_to_index)def__str__(self):returnf"<LabelEncoder(num_classes={len(self)})>"deffit(self,y):classes=np.unique(y)fori,class_inenumerate(classes):self.class_to_index[class_]=iself.index_to_class={v:kfork,vinself.class_to_index.items()}self.classes=list(self.class_to_index.keys())returnselfdefencode(self,y):encoded=np.zeros((len(y)),dtype=int)fori,iteminenumerate(y):encoded[i]=self.class_to_index[item]returnencodeddefdecode(self,y):classes=[]fori,iteminenumerate(y):classes.append(self.index_to_class[item])returnclassesdefsave(self,fp):withopen(fp,"w")asfp:contents={'class_to_index':self.class_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
classTokenizer(object):def__init__(self,char_level,num_tokens=None,pad_token="<PAD>",oov_token="<UNK>",token_to_index=None):self.char_level=char_levelself.separator=""ifself.char_levelelse" "ifnum_tokens:num_tokens-=2# pad + unk tokensself.num_tokens=num_tokensself.pad_token=pad_tokenself.oov_token=oov_tokenifnottoken_to_index:token_to_index={pad_token:0,oov_token:1}self.token_to_index=token_to_indexself.index_to_token={v:kfork,vinself.token_to_index.items()}def__len__(self):returnlen(self.token_to_index)def__str__(self):returnf"<Tokenizer(num_tokens={len(self)})>"deffit_on_texts(self,texts):ifnotself.char_level:texts=[text.split(" ")fortextintexts]all_tokens=[tokenfortextintextsfortokenintext]counts=Counter(all_tokens).most_common(self.num_tokens)self.min_token_freq=counts[-1][1]fortoken,countincounts:index=len(self)self.token_to_index[token]=indexself.index_to_token[index]=tokenreturnselfdeftexts_to_sequences(self,texts):sequences=[]fortextintexts:ifnotself.char_level:text=text.split(" ")sequence=[]fortokenintext:sequence.append(self.token_to_index.get(token,self.token_to_index[self.oov_token]))sequences.append(np.asarray(sequence))returnsequencesdefsequences_to_texts(self,sequences):texts=[]forsequenceinsequences:text=[]forindexinsequence:text.append(self.index_to_token.get(index,self.oov_token))texts.append(self.separator.join([tokenfortokenintext]))returntextsdefsave(self,fp):withopen(fp,"w")asfp:contents={"char_level":self.char_level,"oov_token":self.oov_token,"token_to_index":self.token_to_index}json.dump(contents,fp,indent=4,sort_keys=False)@classmethoddefload(cls,fp):withopen(fp,"r")asfp:kwargs=json.load(fp=fp)returncls(**kwargs)
Warning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Sample of tokensprint(take(5,tokenizer.token_to_index.items()))print(f"least freq token's freq: {tokenizer.min_token_freq}")# use this to adjust num_tokens
# Convert texts to sequences of indicesX_train=tokenizer.texts_to_sequences(X_train)X_val=tokenizer.texts_to_sequences(X_val)X_test=tokenizer.texts_to_sequences(X_test)preprocessed_text=tokenizer.sequences_to_texts([X_train[0]])[0]print("Text to indices:\n"f" (preprocessed) → {preprocessed_text}\n"f" (tokenized) → {X_train[0]}")
Text to indices:
(preprocessed) → nba wrap neal <UNK> 40 heat <UNK> wizards
(tokenized) → [ 299 359 3869 1 1648 734 1 2021]
Each token in the input is represented via embeddings (all out-of-vocabulary (OOV) tokens are given the embedding for UNK token.) In the model below, we'll see how to set these embeddings to be pretrained GloVe embeddings and how to choose whether to freeze (fixed embedding weights) those embeddings or not during training.
Padding
Our inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
While embedding our input tokens will create a batch of shape (N, max_seq_len, embed_dim) we only need to provide a 2D matrix (N, max_seq_len) for using embeddings with PyTorch.
1234567
defpad_sequences(sequences,max_seq_len=0):"""Pad sequences to max length in sequence."""max_seq_len=max(max_seq_len,max(len(sequence)forsequenceinsequences))padded_sequences=np.zeros((len(sequences),max_seq_len))fori,sequenceinenumerate(sequences):padded_sequences[i][:len(sequence)]=sequencereturnpadded_sequences
classDataset(torch.utils.data.Dataset):def__init__(self,X,y,max_filter_size):self.X=Xself.y=yself.max_filter_size=max_filter_sizedef__len__(self):returnlen(self.y)def__str__(self):returnf"<Dataset(N={len(self)})>"def__getitem__(self,index):X=self.X[index]y=self.y[index]return[X,y]defcollate_fn(self,batch):"""Processing on a batch."""# Get inputsbatch=np.array(batch)X=batch[:,0]y=batch[:,1]# Pad sequencesX=pad_sequences(X)# CastX=torch.LongTensor(X.astype(np.int32))y=torch.LongTensor(y.astype(np.int32))returnX,ydefcreate_dataloader(self,batch_size,shuffle=False,drop_last=False):returntorch.utils.data.DataLoader(dataset=self,batch_size=batch_size,collate_fn=self.collate_fn,shuffle=shuffle,drop_last=drop_last,pin_memory=True)
1 2 3 4 5 6 7 8 9101112
# Create datasetsmax_filter_size=max(FILTER_SIZES)train_dataset=Dataset(X=X_train,y=y_train,max_filter_size=max_filter_size)val_dataset=Dataset(X=X_val,y=y_val,max_filter_size=max_filter_size)test_dataset=Dataset(X=X_test,y=y_test,max_filter_size=max_filter_size)print("Datasets:\n"f" Train dataset:{train_dataset.__str__()}\n"f" Val dataset: {val_dataset.__str__()}\n"f" Test dataset: {test_dataset.__str__()}\n""Sample point:\n"f" X: {train_dataset[0][0]}\n"f" y: {train_dataset[0][1]}")
We'll be using a convolutional neural network on top of our embedded tokens to extract meaningful spatial signal. This time, we'll be using many filter widths to act as n-gram feature extractors.
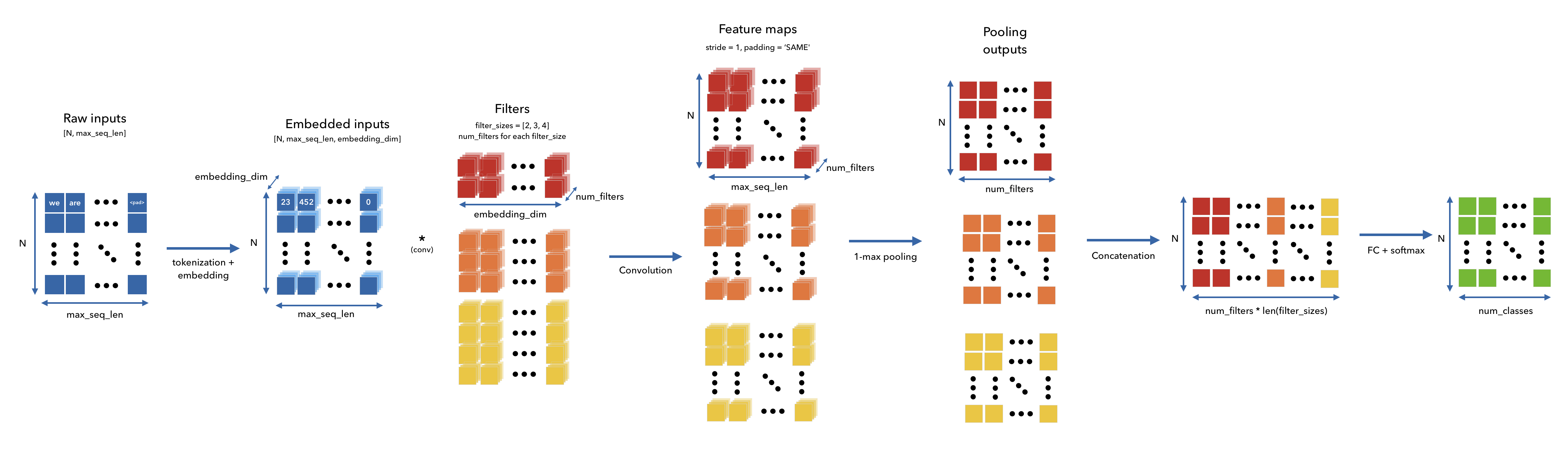
Let's visualize the model's forward pass.
We'll first tokenize our inputs (batch_size, max_seq_len).
Then we'll embed our tokenized inputs (batch_size, max_seq_len, embedding_dim).
We'll apply convolution via filters (filter_size, embedding_dim, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors. We have three different filter sizes (2, 3 and 4) and they will act as bi-gram, tri-gram and 4-gram feature extractors, respectively.
We'll apply 1D global max pooling which will extract the most relevant information from the feature maps for making the decision.
We feed the pool outputs to a fully-connected (FC) layer (with dropout).
We use one more FC layer with softmax to derive class probabilities.
classCNN(nn.Module):def__init__(self,embedding_dim,vocab_size,num_filters,filter_sizes,hidden_dim,dropout_p,num_classes,pretrained_embeddings=None,freeze_embeddings=False,padding_idx=0):super(CNN,self).__init__()# Filter sizesself.filter_sizes=filter_sizes# Initialize embeddingsifpretrained_embeddingsisNone:self.embeddings=nn.Embedding(embedding_dim=embedding_dim,num_embeddings=vocab_size,padding_idx=padding_idx)else:pretrained_embeddings=torch.from_numpy(pretrained_embeddings).float()self.embeddings=nn.Embedding(embedding_dim=embedding_dim,num_embeddings=vocab_size,padding_idx=padding_idx,_weight=pretrained_embeddings)# Freeze embeddings or notiffreeze_embeddings:self.embeddings.weight.requires_grad=False# Conv weightsself.conv=nn.ModuleList([nn.Conv1d(in_channels=embedding_dim,out_channels=num_filters,kernel_size=f)forfinfilter_sizes])# FC weightsself.dropout=nn.Dropout(dropout_p)self.fc1=nn.Linear(num_filters*len(filter_sizes),hidden_dim)self.fc2=nn.Linear(hidden_dim,num_classes)defforward(self,inputs,channel_first=False):# Embedx_in,=inputsx_in=self.embeddings(x_in)# Rearrange input so num_channels is in dim 1 (N, C, L)ifnotchannel_first:x_in=x_in.transpose(1,2)# Conv outputsz=[]max_seq_len=x_in.shape[2]fori,finenumerate(self.filter_sizes):# `SAME` paddingpadding_left=int((self.conv[i].stride[0]*(max_seq_len-1)-max_seq_len+self.filter_sizes[i])/2)padding_right=int(math.ceil((self.conv[i].stride[0]*(max_seq_len-1)-max_seq_len+self.filter_sizes[i])/2))# Conv + pool_z=self.conv[i](F.pad(x_in,(padding_left,padding_right)))_z=F.max_pool1d(_z,_z.size(2)).squeeze(2)z.append(_z)# Concat conv outputsz=torch.cat(z,1)# FC layersz=self.fc1(z)z=self.dropout(z)z=self.fc2(z)returnz
Using GloVe
We're going create some utility functions to be able to load the pretrained GloVe embeddings into our Embeddings layer.
1 2 3 4 5 6 7 8 910
defload_glove_embeddings(embeddings_file):"""Load embeddings from a file."""embeddings={}withopen(embeddings_file,"r")asfp:forindex,lineinenumerate(fp):values=line.split()word=values[0]embedding=np.asarray(values[1:],dtype='float32')embeddings[word]=embeddingreturnembeddings
12345678
defmake_embeddings_matrix(embeddings,word_index,embedding_dim):"""Create embeddings matrix to use in Embedding layer."""embedding_matrix=np.zeros((len(word_index),embedding_dim))forword,iinword_index.items():embedding_vector=embeddings.get(word)ifembedding_vectorisnotNone:embedding_matrix[i]=embedding_vectorreturnembedding_matrix
We have first have to decide whether to use pretrained embeddings randomly initialized ones. Then, we can choose to freeze our embeddings or continue to train them using the supervised data (this could lead to overfitting). Here are the three experiments we're going to conduct:
classTrainer(object):def__init__(self,model,device,loss_fn=None,optimizer=None,scheduler=None):# Set paramsself.model=modelself.device=deviceself.loss_fn=loss_fnself.optimizer=optimizerself.scheduler=schedulerdeftrain_step(self,dataloader):"""Train step."""# Set model to train modeself.model.train()loss=0.0# Iterate over train batchesfori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,targets=batch[:-1],batch[-1]self.optimizer.zero_grad()# Reset gradientsz=self.model(inputs)# Forward passJ=self.loss_fn(z,targets)# Define lossJ.backward()# Backward passself.optimizer.step()# Update weights# Cumulative Metricsloss+=(J.detach().item()-loss)/(i+1)returnlossdefeval_step(self,dataloader):"""Validation or test step."""# Set model to eval modeself.model.eval()loss=0.0y_trues,y_probs=[],[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Stepbatch=[item.to(self.device)foriteminbatch]# Set deviceinputs,y_true=batch[:-1],batch[-1]z=self.model(inputs)# Forward passJ=self.loss_fn(z,y_true).item()# Cumulative Metricsloss+=(J-loss)/(i+1)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)y_trues.extend(y_true.cpu().numpy())returnloss,np.vstack(y_trues),np.vstack(y_probs)defpredict_step(self,dataloader):"""Prediction step."""# Set model to eval modeself.model.eval()y_probs=[]# Iterate over val batcheswithtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]z=self.model(inputs)# Store outputsy_prob=F.softmax(z).cpu().numpy()y_probs.extend(y_prob)returnnp.vstack(y_probs)deftrain(self,num_epochs,patience,train_dataloader,val_dataloader):best_val_loss=np.infforepochinrange(num_epochs):# Stepstrain_loss=self.train_step(dataloader=train_dataloader)val_loss,_,_=self.eval_step(dataloader=val_dataloader)self.scheduler.step(val_loss)# Early stoppingifval_loss<best_val_loss:best_val_loss=val_lossbest_model=self.model_patience=patience# reset _patienceelse:_patience-=1ifnot_patience:# 0print("Stopping early!")break# Loggingprint(f"Epoch: {epoch+1} | "f"train_loss: {train_loss:.5f}, "f"val_loss: {val_loss:.5f}, "f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "f"_patience: {_patience}")returnbest_model
# Initialize modelmodel=CNN(embedding_dim=EMBEDDING_DIM,vocab_size=VOCAB_SIZE,num_filters=NUM_FILTERS,filter_sizes=FILTER_SIZES,hidden_dim=HIDDEN_DIM,dropout_p=DROPOUT_P,num_classes=NUM_CLASSES,pretrained_embeddings=PRETRAINED_EMBEDDINGS,freeze_embeddings=FREEZE_EMBEDDINGS)model=model.to(device)# set deviceprint(model.named_parameters)
# Initialize modelmodel=CNN(embedding_dim=EMBEDDING_DIM,vocab_size=VOCAB_SIZE,num_filters=NUM_FILTERS,filter_sizes=FILTER_SIZES,hidden_dim=HIDDEN_DIM,dropout_p=DROPOUT_P,num_classes=NUM_CLASSES,pretrained_embeddings=PRETRAINED_EMBEDDINGS,freeze_embeddings=FREEZE_EMBEDDINGS)model=model.to(device)# set deviceprint(model.named_parameters)
# Initialize modelmodel=CNN(embedding_dim=EMBEDDING_DIM,vocab_size=VOCAB_SIZE,num_filters=NUM_FILTERS,filter_sizes=FILTER_SIZES,hidden_dim=HIDDEN_DIM,dropout_p=DROPOUT_P,num_classes=NUM_CLASSES,pretrained_embeddings=PRETRAINED_EMBEDDINGS,freeze_embeddings=FREEZE_EMBEDDINGS)model=model.to(device)# set deviceprint(model.named_parameters)
# Save artifactsfrompathlibimportPathdir=Path("cnn")dir.mkdir(parents=True,exist_ok=True)label_encoder.save(fp=Path(dir,"label_encoder.json"))tokenizer.save(fp=Path(dir,"tokenizer.json"))torch.save(best_model.state_dict(),Path(dir,"model.pt"))withopen(Path(dir,"performance.json"),"w")asfp:json.dump(performance,indent=2,sort_keys=False,fp=fp)
Inference
12345678
defget_probability_distribution(y_prob,classes):"""Create a dict of class probabilities from an array."""results={}fori,class_inenumerate(classes):results[class_]=np.float64(y_prob[i])sorted_results={k:vfork,vinsorted(results.items(),key=lambdaitem:item[1],reverse=True)}returnsorted_results
# Dataloadertext="The final tennis tournament starts next week."X=tokenizer.texts_to_sequences([preprocess(text)])print(tokenizer.sequences_to_texts(X))y_filler=label_encoder.encode([label_encoder.classes[0]]*len(X))dataset=Dataset(X=X,y=y_filler,max_filter_size=max_filter_size)dataloader=dataset.create_dataloader(batch_size=batch_size)
We went through all the trouble of padding our inputs before convolution to result is outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
# Get conv outputsinterpretable_model.eval()conv_outputs=[]withtorch.inference_mode():fori,batchinenumerate(dataloader):# Forward pass w/ inputsinputs,targets=batch[:-1],batch[-1]z=interpretable_model(inputs)# Store conv outputsconv_outputs.extend(z)conv_outputs=np.vstack(conv_outputs)print(conv_outputs.shape)# (len(filter_sizes), num_filters, max_seq_len)
(3, 50, 6)
1234
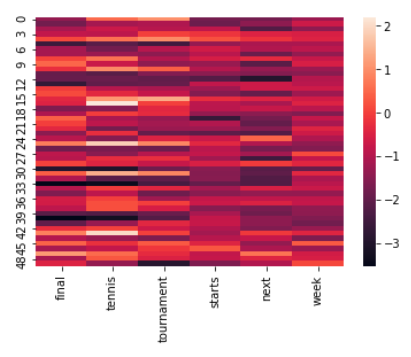
# Visualize a bi-gram filter's outputstokens=tokenizer.sequences_to_texts(X)[0].split(" ")filter_size=2sns.heatmap(conv_outputs[filter_size-1][:,len(tokens)],xticklabels=tokens)
1D global max-pooling would extract the highest value from each of our num_filters for each filter_size. We could also follow this same approach to figure out which n-gram is most relevant but notice in the heatmap above that many filters don't have much variance. To mitigate this, this paper uses threshold values to determine which filters to use for interpretability. But to keep things simple, let's extract which tokens' filter outputs were extracted via max-pooling the most frequently.
1 2 3 4 5 6 7 8 9101112131415
sample_index=0print(f"Original text:\n{text}")print(f"\nPreprocessed text:\n{tokenizer.sequences_to_texts(X)[0]}")print("\nMost important n-grams:")# Process conv outputs for each unique filter sizefori,filter_sizeinenumerate(FILTER_SIZES):# Identify most important n-gram (excluding last token)popular_indices=collections.Counter([np.argmax(conv_output) \
forconv_outputinconv_outputs[i]])# Get corresponding textstart=popular_indices.most_common(1)[-1][0]n_gram=" ".join([tokenfortokenintokens[start:start+filter_size]])print(f"[{filter_size}-gram]: {n_gram}")
Original text:
The final tennis tournament starts next week.
Preprocessed text:
final tennis tournament starts next week
Most important n-grams:
[1-gram]: tennis
[2-gram]: tennis tournament
[3-gram]: final tennis tournament
To cite this content, please use:
123456
@article{madewithml,author={Goku Mohandas},title={ Embeddings - Made With ML },howpublished={\url{https://madewithml.com/}},year={2023}}