Data Augmentation

Subscribe to our newsletter
📬 Receive new lessons straight to your inbox (once a month) and join 40K+ developers in learning how to responsibly deliver value with ML.
Intuition
We'll often want to increase the size and diversity of our training data split through data augmentation. It involves using the existing samples to generate synthetic, yet realistic, examples.
-
Split the dataset. We want to split our dataset first because many augmentation techniques will cause a form of data leak if we allow the generated samples to be placed across different data splits.
For example, some augmentation involves generating synonyms for certain key tokens in a sentence. If we allow the generated sentences from the same origin sentence to go into different splits, we could be potentially leaking samples with nearly identical embedding representations across our different splits.
-
Augment the training split. We want to apply data augmentation on only the training set because our validation and testing splits should be used to provide an accurate estimate on actual data points.
-
Inspect and validate. It's useless to augment just for the same of increasing our training sample size if the augmented data samples are not probable inputs that our model could encounter in production.
The exact method of data augmentation depends largely on the type of data and the application. Here are a few ways different modalities of data can be augmented:
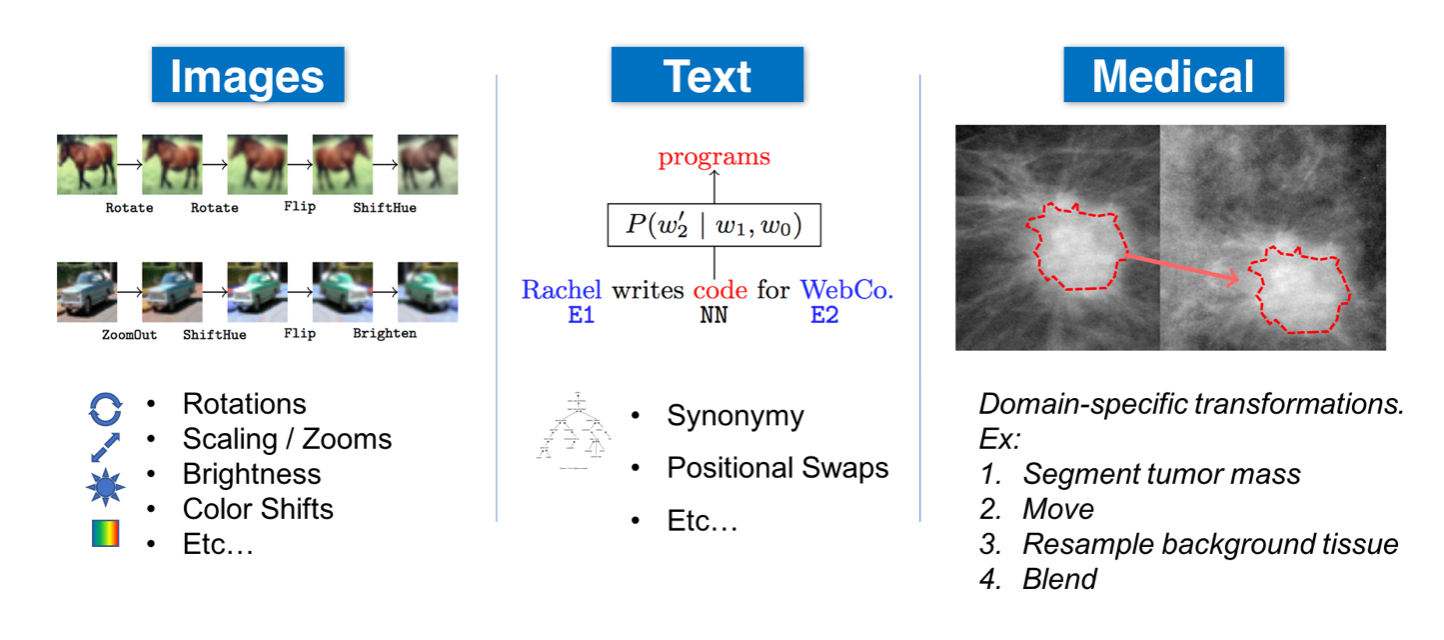
- General: normalization, smoothing, random noise, synthetic oversampling (SMOTE), etc.
- Natural language processing (NLP): substitutions (synonyms, tfidf, embeddings, masked models), random noise, spelling errors, etc.
- Computer vision (CV): crop, flip, rotate, pad, saturate, increase brightness, etc.
Warning
While the transformations on some data modalities, such as images, are easy to inspect and validate, others may introduce silent errors. For example, shifting the order of tokens in text can significantly alter the meaning (“this is really cool” → “is this really cool”). Therefore, it’s important to measure the noise that our augmentation policies will introduce and do have granular control over the transformations that take place.
Libraries
Depending on the feature types and tasks, there are many data augmentation libraries which allow us to extend our training data.
Natural language processing (NLP)
- NLPAug: data augmentation for NLP.
- TextAttack: a framework for adversarial attacks, data augmentation, and model training in NLP.
- TextAugment: text augmentation library.
Computer vision (CV)
- Imgaug: image augmentation for machine learning experiments.
- Albumentations: fast image augmentation library.
- Augmentor: image augmentation library in Python for machine learning.
- Kornia.augmentation: a module to perform data augmentation in the GPU.
- SOLT: data augmentation library for Deep Learning, which supports images, segmentation masks, labels and key points.
Other
- Snorkel: system for generating training data with weak supervision.
- DeltaPy: tabular data augmentation and feature engineering.
- Audiomentations: a Python library for audio data augmentation.
- Tsaug: a Python package for time series augmentation.
Implementation
Let's use the nlpaug library to augment our dataset and assess the quality of the generated samples.
pip install nlpaug==1.1.0 transformers==3.0.2 -q
pip install snorkel==0.9.8 -q
1 | |
1 2 3 4 | |
1 2 | |
hierarchical risk mapping using variational signals and gans.
Substitution doesn't seem like a great idea for us because there are certain keywords that provide strong signal for our tags so we don't want to alter those. Also, note that these augmentations are NOT deterministic and will vary every time we run them. Let's try insertion...
1 2 | |
automated conditional inverse image generation algorithms using multiple variational autoencoders and gans.
A little better but still quite fragile and now it can potentially insert key words that can influence false positive tags to appear. Maybe instead of substituting or inserting new tokens, let's try simply swapping machine learning related keywords with their aliases. We'll use Snorkel's transformation functions to easily achieve this.
1 2 3 | |
1 2 3 4 5 6 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 | |
['nlp', 'nlproc'] ['nlproc', 'natural language processing']
For now we'll use tags and aliases as they are in
aliases_by_tagbut we could account for plurality of tags using the inflect package or apply stemming before replacing aliases, etc.
1 2 3 | |
1 2 3 4 5 | |
1 2 3 | |
<re.Match object; span=(10, 13), match='gan'> None
Now let's use snorkel's transformation_function to systematically apply this transformation to our data.
1 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 | |
1 2 3 4 5 | |
autogenerate vision apply jobs using nlp autogenerate cv apply jobs using natural language processing autogenerate cv apply jobs using nlproc
Now we'll define a augmentation policy to apply our transformation functions with certain rules (how many samples to generate, whether to keep the original data point, etc.)
1 | |
1 2 3 4 5 6 | |
1 | |
(668, 913)
For now, we'll skip the data augmentation because it's quite fickle and empirically it doesn't improvement performance much. But we can see how this can be very effective once we can control what type of vocabulary to augment on and what exactly to augment with.
Warning
Regardless of what method we use, it's important to validate that we're not just augmenting for the sake of augmentation. We can do this by executing any existing data validation tests and even creating specific tests to apply on augmented data.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
To cite this content, please use:
1 2 3 4 5 6 | |