Data Labeling
Repository · Notebook

Subscribe to our newsletter
📬 Receive new lessons straight to your inbox (once a month) and join 40K+ developers in learning how to responsibly deliver value with ML.
What is data labeling
Labeling (or annotation) is the process of identifying the inputs and outputs that are worth modeling (not just what could be modeled).
- use objective as a guide to determine the necessary signals.
- explore creating new signals (via combining features, collecting new data, etc.).
- iteratively add more features to justify complexity and effort.
It's really important to get our labeling workflows in place before we start performing downstream tasks such as data augmentation, model training, etc.
Warning
Be careful not to include features in the dataset that will not be available during prediction, causing data leaks.
What else can we learn?
It's not just about identifying and labeling our initial dataset. What else can we learn from it?
Show answer
It's also the phase where we can use our deep understanding of the problem to:
- augment the training data split
- enhance using auxiliary datasets
- simplify using constraints
- remove noisy samples
- improve the labeling process
Process
Regardless of whether we have a custom labeling platform or we choose a generalized platform, the process of labeling and all it's related workflows (QA, data import/export, etc.) follow a similar approach.
Preliminary steps
[WHAT]Decide what needs to be labeled:- identify natural labels you may already have (ex. time-series)
- consult with domain experts to ensure you're labeling the appropriate signals
- decide on the appropriate labels (and hierarchy) for your task
[WHERE]Design the labeling interface:- intuitive, data modality dependent and quick (keybindings are a must!)
- avoid option paralysis by allowing the labeler to dig deeper or suggesting likely labels
- measure and resolve inter-labeler discrepancy
[HOW]Compose labeling instructions:- examples of each labeling scenario
- course of action for discrepancies
Workflow setup
- Establish data pipelines:
[IMPORT]new data for annotation[EXPORT]annotated data for QA, testing, modeling, etc.
- Create a quality assurance (QA) workflow:
- separate from labeling workflow (no bias)
- communicates with labeling workflow to escalate errors
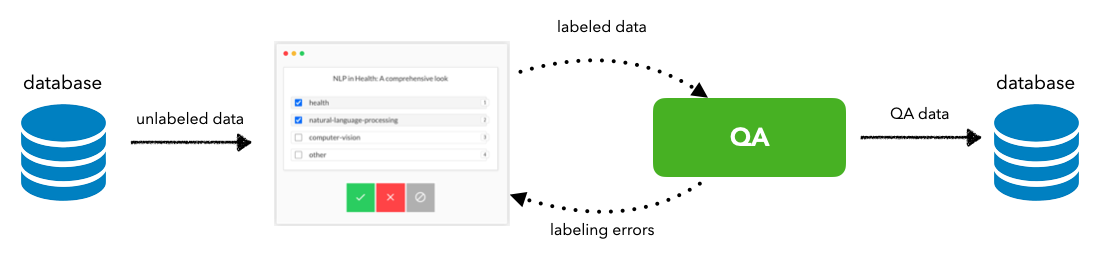
Iterative setup
- Implement strategies to reduce labeling efforts
- identify subsets of the data to label next using active learning
- auto-label entire or parts of a dataset using weak supervision
- focus labeling efforts on long tail of edge cases over time
Labeled data
For the purpose of this course, our data is already labeled, so we'll perform a basic version of ELT (extract, load, transform) to construct the labeled dataset.
In our data-stack and orchestration lessons, we'll construct a modern data stack and programmatically deliver high quality data via DataOps workflows.
- projects.csv: projects with id, created time, title and description.
- tags.csv: labels (tag category) for the projects by id.
Recall that our objective was to classify incoming content so that the community can discover them easily. These data assets will act as the training data for our first model.
Extract
We'll start by extracting data from our sources (external CSV files). Traditionally, our data assets will be stored, versioned and updated in a database, warehouse, etc. We'll learn more about these different data systems later, but for now, we'll load our data as a stand-alone CSV file.
1 | |
1 2 3 4 | |
We'll also load the labels (tag category) for our projects.
1 2 3 4 | |
Transform
Apply basic transformations to create our labeled dataset.
1 2 3 | |
1 | |
Load
Finally, we'll load our transformed data locally so that we can use it for our machine learning application.
1 2 | |
Libraries
We could have used the user provided tags as our labels but what if the user added a wrong tag or forgot to add a relevant one. To remove this dependency on the user to provide the gold standard labels, we can leverage labeling tools and platforms. These tools allow for quick and organized labeling of the dataset to ensure its quality. And instead of starting from scratch and asking our labeler to provide all the relevant tags for a given project, we can provide the author's original tags and ask the labeler to add / remove as necessary. The specific labeling tool may be something that needs to be custom built or leverages something from the ecosystem.
As our platform grows, so too will our dataset and labeling needs so it's imperative to use the proper tooling that supports the workflows we'll depend on.
General
- Labelbox: the data platform for high quality training and validation data for AI applications.
- Scale AI: data platform for AI that provides high quality training data.
- Label Studio: a multi-type data labeling and annotation tool with standardized output format.
- Universal Data Tool: collaborate and label any type of data, images, text, or documents in an easy web interface or desktop app.
- Prodigy: recipes for the Prodigy, our fully scriptable annotation tool.
- Superintendent: an ipywidget-based interactive labelling tool for your data to enable active learning.
Natural language processing
- Doccano: an open source text annotation tool for text classification, sequence labeling and sequence to sequence tasks.
- BRAT: a rapid annotation tool for all your textual annotation needs.
Computer vision
- LabelImg: a graphical image annotation tool and label object bounding boxes in images.
- CVAT: a free, online, interactive video and image annotation tool for computer vision.
- VoTT: an electron app for building end-to-end object detection models from images and videos.
- makesense.ai: a free to use online tool for labelling photos.
- remo: an app for annotations and images management in computer vision.
- Labelai: an online tool designed to label images, useful for training AI models.
Audio
- Audino: an open source audio annotation tool for voice activity detection (VAD), diarization, speaker identification, automated speech recognition, emotion recognition tasks, etc.
- audio-annotator: a JavaScript interface for annotating and labeling audio files.
- EchoML: a web app to play, visualize, and annotate your audio files for machine learning.
Miscellaneous
- MedCAT: a medical concept annotation tool that can extract information from Electronic Health Records (EHRs) and link it to biomedical ontologies like SNOMED-CT and UMLS.
Generalized labeling solutions
What criteria should we use to evaluate what labeling platform to use?
Show answer
It's important to pick a generalized platform that has all the major labeling features for your data modality with the capability to easily customize the experience.
- how easy is it to connect to our data sources (DB, QA, etc.)?
- how easy was it to make changes (new features, labeling paradigms)?
- how securely is our data treated (on-prem, trust, etc.)
However, as an industry trend, this balance between generalization and specificity is difficult to strike. So many teams put in the upfront effort to create bespoke labeling platforms or used industry specific, niche, labeling tools.
Active learning
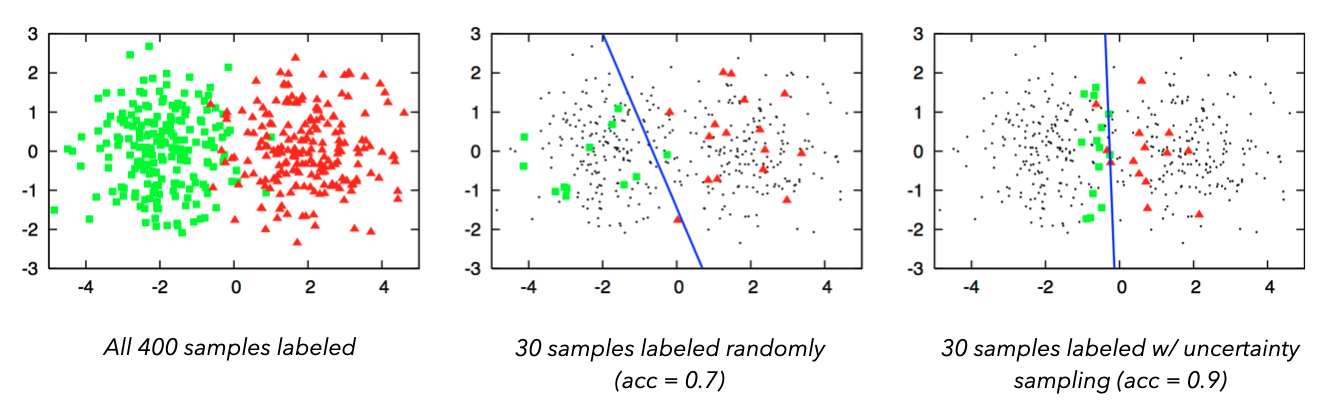
Even with a powerful labeling tool and established workflows, it's easy to see how involved and expensive labeling can be. Therefore, many teams employ active learning to iteratively label the dataset and evaluate the model.
- Label a small, initial dataset to train a model.
- Ask the trained model to predict on some unlabeled data.
- Determine which new data points to label from the unlabeled data based on:
- entropy over the predicted class probabilities
- samples with lowest predicted, calibrated, confidence (uncertainty sampling)
- discrepancy in predictions from an ensemble of trained models
- Repeat until the desired performance is achieved.
This can be significantly more cost-effective and faster than labeling the entire dataset.
Libraries
- modAL: a modular active learning framework for Python.
- libact: pool-based active learning in Python.
- ALiPy: active learning python toolbox, which allows users to conveniently evaluate, compare and analyze the performance of active learning methods.
Weak supervision
If we had samples that needed labeling or if we simply wanted to validate existing labels, we can use weak supervision to generate labels as opposed to hand labeling all of them. We could utilize weak supervision via labeling functions to label our existing and new data, where we can create constructs based on keywords, pattern expressions, knowledge bases, etc. And we can add to the labeling functions over time and even mitigate conflicts amongst the different labeling functions. We'll use these labeling functions to create and evaluate slices of our data in the evaluation lesson.
1 2 3 4 5 6 | |
An easy way to validate our labels (before modeling) is to use the aliases in our auxillary datasets to create labeling functions for the different classes. Then we can look for false positives and negatives to identify potentially mislabeled samples. We'll actually implement a similar kind of inspection approach, but using a trained model as a heuristic, in our dashboards lesson.
Iteration
Labeling isn't just a one time event or something we repeat identically. As new data is available, we'll want to strategically label the appropriate samples and improve slices of our data that are lacking in quality. Once new data is labeled, we can have workflows that are triggered to start the (re)training process to deploy a new version of our system.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
To cite this content, please use:
1 2 3 4 5 6 | |